
Spatial Disaggregation Event
The Spatial Disaggregation event takes a hydrology ensemble consisting of trace folders, each containing a file of flow data for a single site, and spatially disaggregates the site flow data, resulting in trace folders that contain files of flow data for multiple sites. These trace flow files can then be imported through a DMI to a RiverWare multiple run.
Note: For the Spatial Disaggregation event to successfully disaggregate flow data, the R Project for Statistical Computing must be installed on your computer; see Install R and Component Packages for details. This event was developed and tested with R version 2.14.2, but it should work with newer versions of R.
The general algorithm for the spatial disaggregation is as follows.
1. For each timestep in the trace, a k-NN sampling is used to select a timestep from the pattern data that has aggregated flow similar to the simulated annual flow.
2. From the selected timestep in the pattern data, the individual location flows are used to calculate the percentage of aggregated flow for each location.
3. The individual location percentages are applied the aggregated trace flow value allocate the total flow to individual locations.
4. The process is repeated for all timesteps in the trace.
Spatial Disagg Window
This window opens when you open a Spatial Disaggregation event on the RiverSMART workspace.
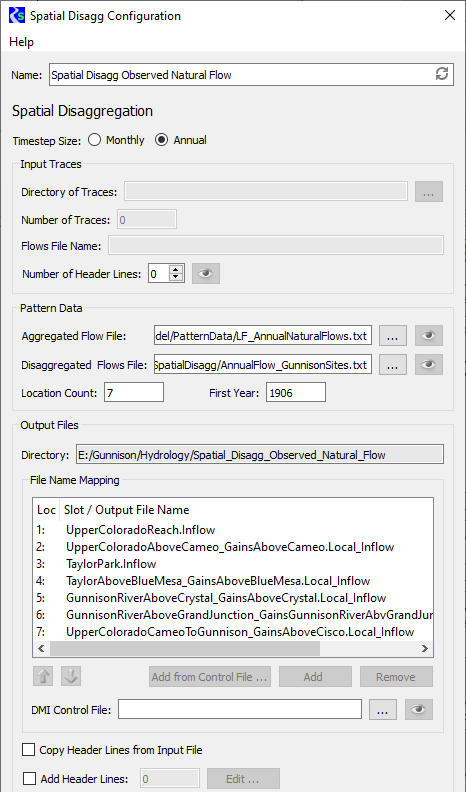
Name
Enter a user-defined unique name for the Spatial Disaggregation event.
Timestep Size
Select the appropriate option to specify whether the input ensemble data is monthly or annual data.
Input Traces frame
In this frame, you specify information about the ensemble of trace data that is input to the Spatial Disaggregation process.
• If the Spatial Disaggregation event is linked on the input side, the Directory, Number of Traces, and Flows File Name fields are not available (dimmed); they are automatically completed when the upstream event is generated.
• If the Spatial Disaggregation event is not linked on the input side, these fields are enabled and you must complete them; all are required.
Directory of Traces
Specify the folder that includes all trace folders for the input ensemble. You can enter the path or select it through the File Chooser.
Number of Traces
Enter the number of traces in the ensemble.
Flows File Name
Enter the name of the site data file that is in each trace folder. A site data file should be a single time series of flows for the desired site.
Number of Header Lines
Enter the number of non-data header lines in the site data file. The R scripts expect the file to start with data values; therefore, if there are header lines, this entry is required to inform the scripts how many lines to skip. If you need to see how many header lines there are, select Preview to preview in a separate window a sample site data file for trace1, if the file exists.
Pattern Data frame
In this frame, you provide data to define the pattern for spatially disaggregating the input site.
Aggregated Flow File
Specify a file that includes a single time series of historical observed values for the input site. You can enter the path or select it through the File Chooser. To preview the file in a separate window, select Preview.
Disaggregated Flows File
Specify a file that includes a time series of flows for each site to be disaggregated to. The file is structured as columns of data, one column per site, with a single space between columns. Each column represents a time series of historical observed values for one site.
You can enter the path or select it through the File Chooser. To preview the file in a separate window, select Preview.
Location Count
Enter the number of sites to disaggregate to; this must match the number of columns in the Disaggregated Flows File.
First Year
Enter the year of the first observation in the Disaggregated Flows File.
Output Files frame
In this frame, you specify information to configure the output generated by the event.
Directory
Display-only field. Displays the output folder to be created by RiverSMART. This folder is located under the Hydrology subfolder of the study folder, and it is assigned the user-defined Name of the Spatial Disaggregation event. A folder for each trace—named trace1, trace2, and so on—is created under this folder.
File Name Mapping
This list allows you to specify the names of the output files to be generated; enter one name for each site that is disaggregated to.
Note: If the number of entries in the list does not match the specified Location Count, a warning message is displayed above the list.
Use either of the following methods to add an entry to the list.
• Select Add, then open the entry and enter the file name, which is typically the name of the site.
• Enter a DMI Control File to select entries from that file. You can enter the file path in the text box or select it through the File Chooser. To preview the file in a separate window, select Preview.
You can then select Add from Control File to display a list of slot names included in the DMI control file and select the ones to add to the File Name Mapping list. If units are specified in the control file for the site, they are displayed in the list for informational purposes only.
The order of the entries in the File Name Mapping list must match the order of the columns of site data in the Disaggregated Flows File. To reorder selected entries in the list, select the Up or Down arrow to move them one step in that direction. You can remove selected entries from the list by selecting Remove.
Copy Header Lines from Input File
Select the check box to copy the header lines in the input traces to the output files.
Add Header Lines
Select the check box to enter additional header lines to add to the output files. Select Edit, then enter the lines in the Additional Meta Data Lines window and select OK when done. The number of additional lines is displayed in the text box.
Revised: 07/03/2024