
Setting Up a Multiple Run Configuration
This section provides the steps to setting up a multiple run configuration. Setting up a multiple run configuration requires specifying several parameters in the MRM Configuration. The parameters and brief descriptions are provided below.
• Open the Multiple Run Control dialog by selecting Control, then MRM Control Panel from the main RiverWare menu bar or select the MRM button on the toolbar.
• Create a new configuration and edit an existing configuration, as appropriate. See Creating a New Configuration and Editing an Existing Configuration for details.
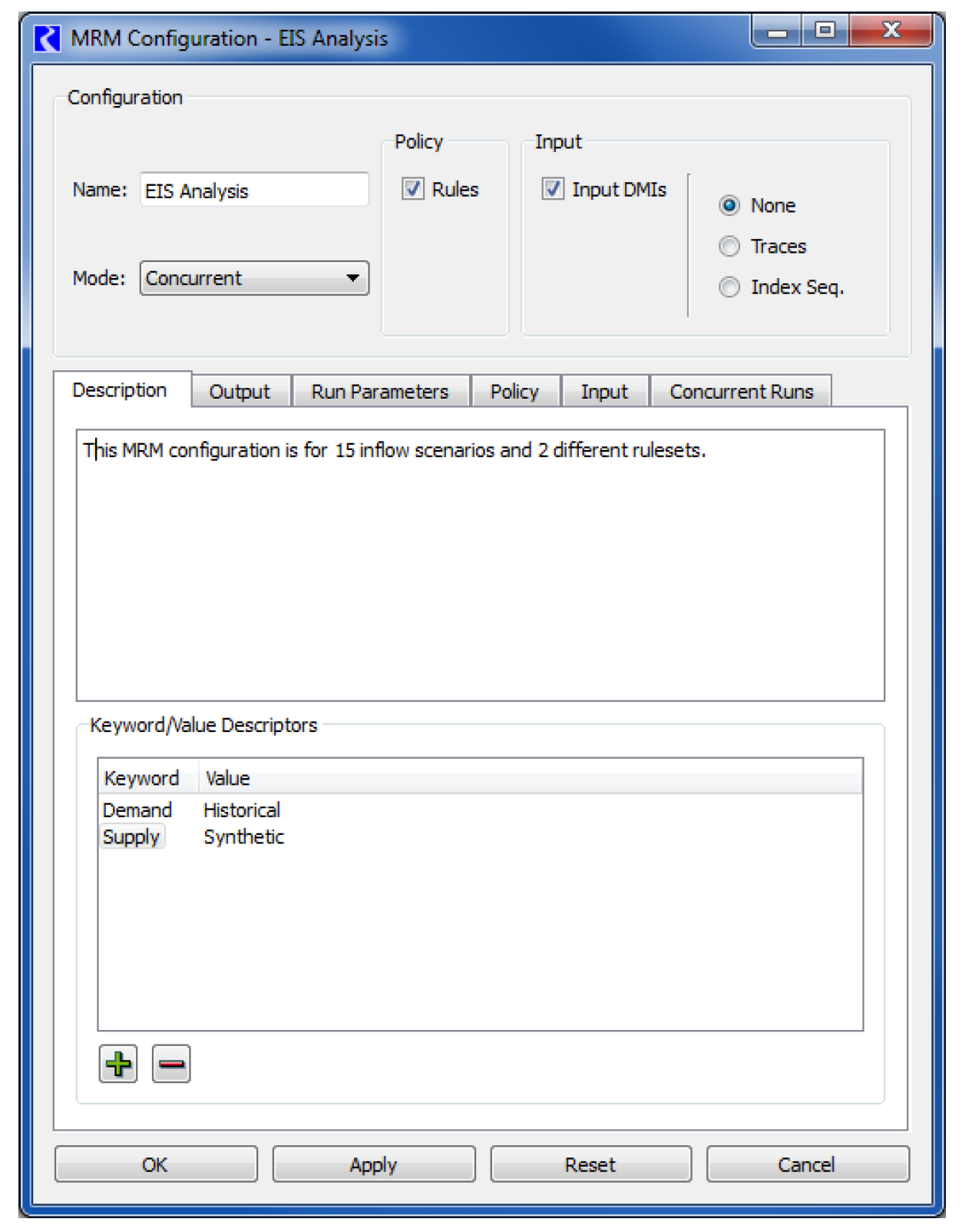
Name
Provide a unique name for the configuration in the Name field.
Description
The configuration description in the upper panel may be multiple lines of text. This first non-blank line of the description appears in an MRM output RDF file. This text is optional, and will not affect the MRM execution if left blank.
Keyword/Value Descriptors are user-entered to describe the MRM configuration. For example, these could indicate something about the data being brought in by DMIs, something about the ruleset, or anything else the user would like to document. These descriptors can optionally be written into CSV or netCDF files output from the multiple run as described. See CSV Files and NetCDF Files for details.
Mode
Select the Mode of the configuration (Concurrent, Consecutive or Iterative) from the Mode menu. Selecting a mode will add the appropriate tabs to the dialog. Configuration of these tabs is described for each of the modes.
Concurrent Runs
Concurrent runs are multiple runs of which the time horizons are identical. The begin and end times, and timestep length, are the same for all runs. Concurrent runs are used to run the model multiple times with different inputs for each run. Inputs include rulesets (policy alternatives), input DMIs (i.e. series data like alternative hydrologies), and/or index sequential (data sampling technique). For concurrent mode, the Run Parameters tab is shown.
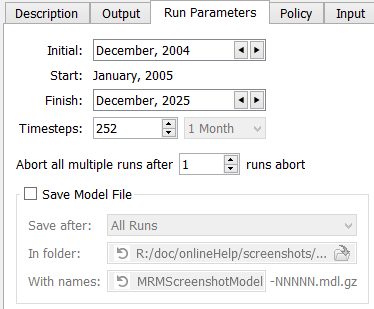
Run Range Controls
The Run Parameters tab describes the initial and end date of each concurrent run. The run parameters also show the timestep size, but timestep size is dependent on the model and can only be changed in the single run control dialog.
Note: The Initial and Finish timestep for a concurrent run can be different than what is shown in the single Run Control.
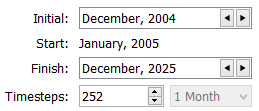
Control to Abort all Multiple Runs after Abort
Use the control to specify how many runs can abort before the total concurrent MRM is stopped. The default is 1, indicating all MRM runs will abort when any single run aborts. Increase this if you want to allow runs to abort but not stop all MRM runs.

During non-distributed concurrent MRM, diagnostic messages will indicate aborted runs. If the number of aborted runs does not cause the concurrent MRM to abort, the diagnostic message is shown as a green information message. If the number of aborted runs causes the concurrent MRM to abort, the diagnostic message is a red error message.
During distributed concurrent MRM, the number of runs which can abort before the concurrent MRM aborts is not per-simulation, it’s the total for all simulations. Consider a concurrent MRM which is configured to allow four traces to abort before the concurrent MRM aborts, and which is distributed across four simulations. Because the aborted trace limit is the total for all simulations, when the fourth trace aborts, the concurrent MRM will abort. This is independent of how the aborted traces are distributed among the simulations. If the user clicks the “show diagnostic messages” button, the messages identify which traces aborted.
See also Simulations for information on how distributed concurrent runs can be stopped when a given simulation stops.
Save Model File
The Run Parameters tab also allows you to configure to save the model after each run. This functionality is useful for debugging or if you want to see the resulting saved model file. To save the model after each run, select the Save Model File option and specify when to save the model, where and the name as follows:
– Save after: select one of the options:
• Successful Runs: This only saves the model for runs that completed successfully.
• Unsuccessful Runs: This saves the model for runs that abort.
• All Runs: Save the model for both successful and unsuccessful runs.
– In folder: select the folder in which to save the runs.
– With names: Specify the base model name. Each model will then be saved with that name and the suffix -NNNNN.mdl.gz. For example, ModelForDebugging-00001.mdl.gz, ModelForDebugging-00002.mdl.gz, etc.
Concurrent Runs tab
• The Concurrent Runs tab shows the number of runs that will be made.
– In most cases, the total number of runs should be the product of the number of rulesets, the number of input DMIs, and the number of index sequential runs:
#of MRM runs = #of Rulesets * #of Input DMIs * #of Index Seq Runs
– If the Pairs option for DMI/Index Sequential Mode has been selected on the Input tab, the total number of runs should equal the number of pairs of Input DMIs and Index Sequential runs. If the number of input DMIs does not match the number of Index Sequential runs, then the number of index sequential runs equals the total number of possible pairs, (i.e., the minimum of the number of input DMIs and the number of Index Sequential runs). (See the Index Sequential / DMI Mode section for more details.)
#of MRM runs = min(#of Input DMIs, #of Index Seq Runs)
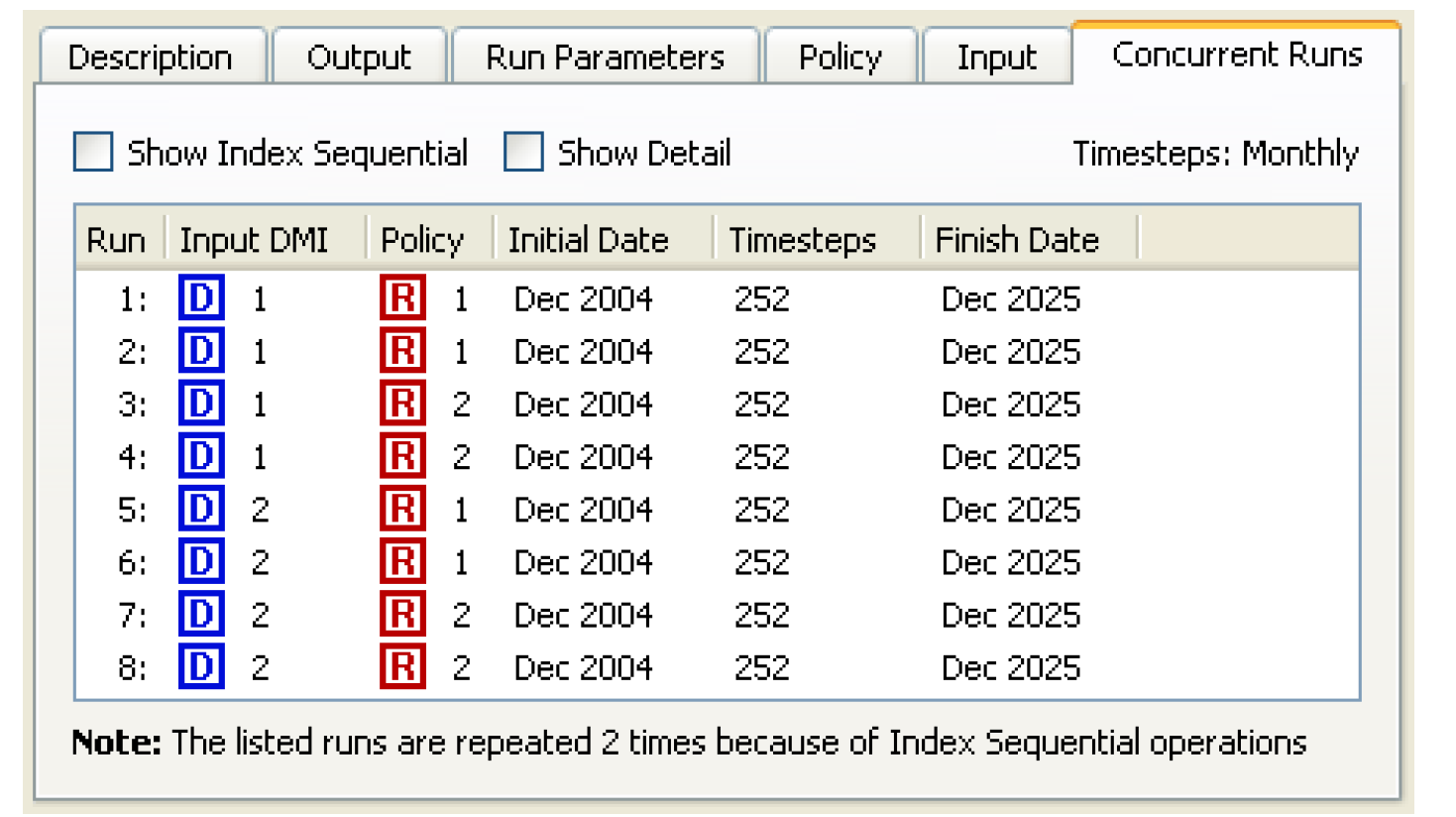
Figure 3.1 shows Concurrent Runs with 2 Input DMIs and 2 policy sets, no Index Sequential.
Figure 3.1
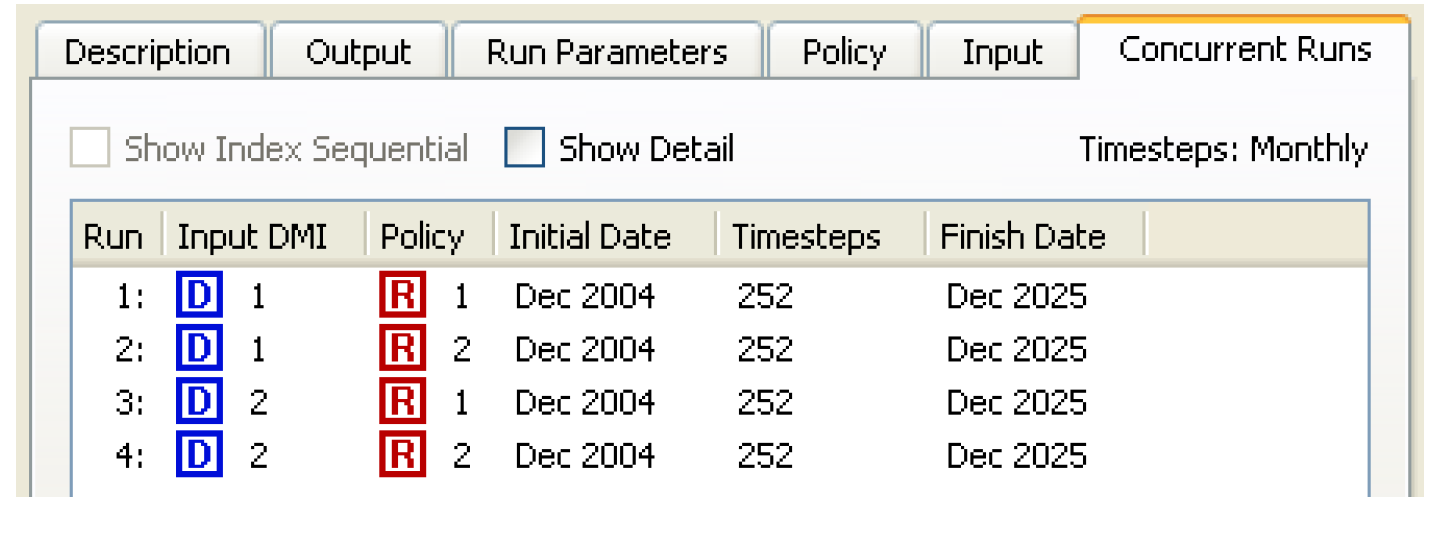
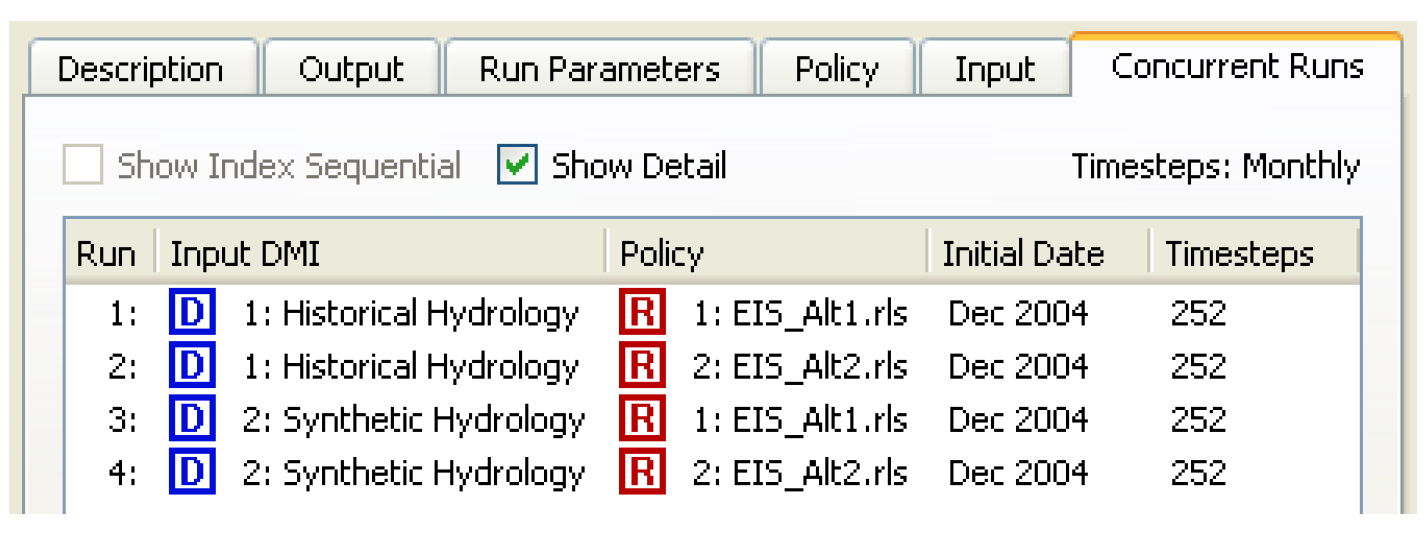
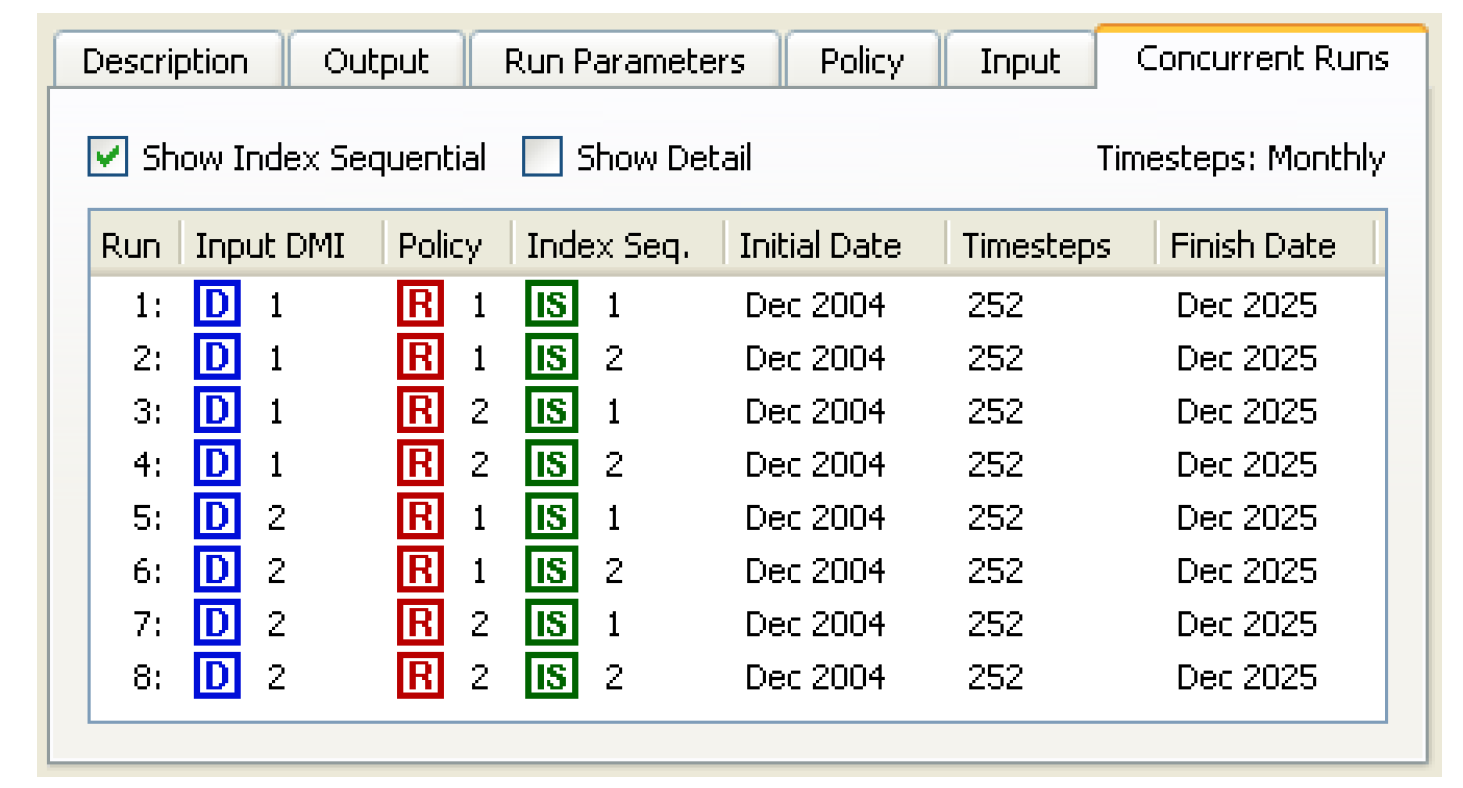
As shown in Figure 3.2, selecting the Show Details checkbox will show the names of the DMIs and policy sets.
Figure 3.2
Consecutive Runs
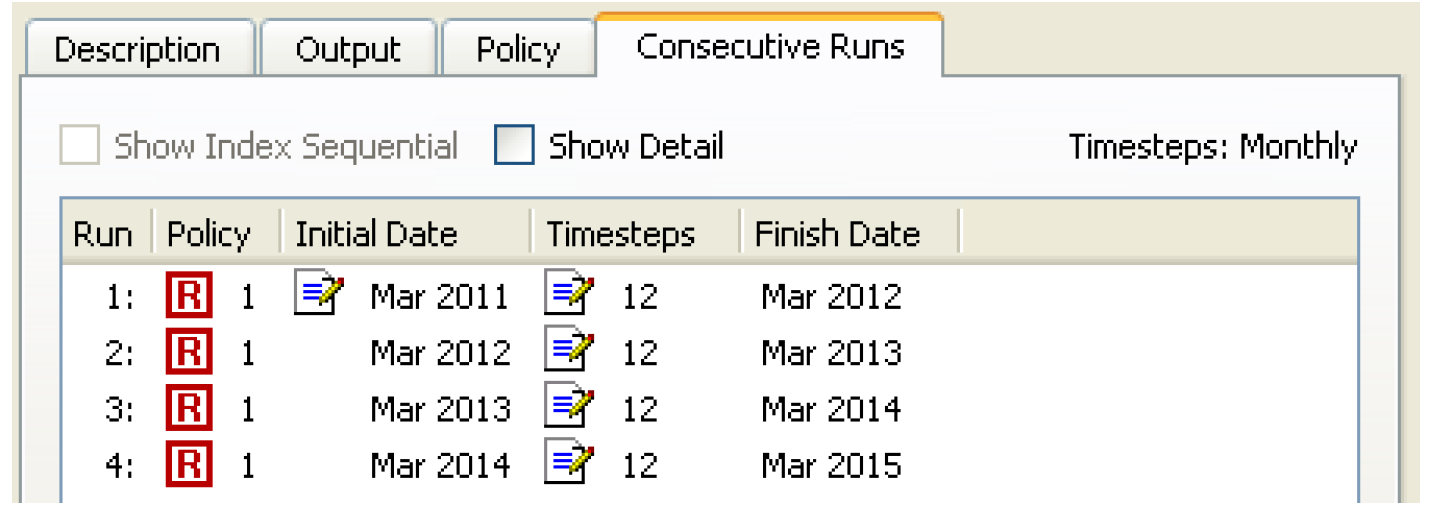
Consecutive runs are multiple runs where the time horizons are laid out consecutively. The end time of one run is the initial time of the next run. Timesteps do not vary among the different runs in a consecutive run.
• On the Consecutive Runs tab, the Edit button indicates which fields in this dialog are editable.  If necessary, change the Initial Date for the consecutive runs. Do this by selecting the existing initial date and toggling the up/down arrows in the ensuing date-time spinner.
If necessary, change the Initial Date for the consecutive runs. Do this by selecting the existing initial date and toggling the up/down arrows in the ensuing date-time spinner.
If necessary, change the Initial Date for the consecutive runs. Do this by selecting the existing initial date and toggling the up/down arrows in the ensuing date-time spinner. • Change the number of timesteps for the first consecutive run by selecting the existing number of timesteps and toggling the up/down arrows of the ensuing integer spinner. The Finish Date automatically updates.
• Append a new row for each desired additional consecutive run by selecting the Plus button. Or right-click below the existing consecutive run and selecting Append Row from the ensuing context menu. The Initial Date is automatically set to match the Finish Date of the previous consecutive run. In the Initial Date column, only the first consecutive run can be changed.
Or right-click below the existing consecutive run and selecting Append Row from the ensuing context menu. The Initial Date is automatically set to match the Finish Date of the previous consecutive run. In the Initial Date column, only the first consecutive run can be changed.
Or right-click below the existing consecutive run and selecting Append Row from the ensuing context menu. The Initial Date is automatically set to match the Finish Date of the previous consecutive run. In the Initial Date column, only the first consecutive run can be changed.• Change the number of timesteps for each individual run, if necessary. The default is for newly appended runs to have the same number of timesteps as the previous run.
• To remove a run, select the Minus button. This will always remove the last run. 
Iterative Runs
Iterative runs are multiple runs where MRM rules at the beginning and/or end of each run examine the state of the system and, if appropriate, set values for the subsequent simulation run. If no values are set or the maximum number of iterations occurs, then the simulation ends. As in concurrent runs, the time horizons, begin and end times and timestep length are all the same for all runs.
The iterative runs can use any of the controllers as specified in the single Run Control dialog: simulation (with or without accounting), rulebased (with or without accounting) or optimization. If the run is rulebased or optimization, the same RPL set or Goal set, respectively, is used in each iteration.
An iterative run executes as follows:
1. Initialize the iteration count.
2. Execute the Pre-MRM Run Rules, if specified.
Note: Pre-MRM Run Rules are similar to Initialization rules for each run; see Initialization Rules Set in RiverWare Policy Language (RPL).
3. Perform a single run.
4. Execute the Post-Run Rules, if specified.
5. If the Post-Run Rules return “no change”, that is they do not assign one or more new (different) values, the iteration is complete.
6. Otherwise, the iteration count is checked. If it equals the maximum number of iterations specified, then the iteration is complete also.
7. If the iteration is not complete, then increment the iteration count and return to Step 3..
When an MRM rule, either pre-run or post-run, sets a value on a slot, the value is given the i flag indicating that it is a “Iterative MRM” flag. Values with the iterative MRM flag are cleared at the beginning of an iterative MRM run but are not cleared between iterations of the MRM. This allows values set by the iterative MRM rules to persist between iterations but values are cleared at the beginning of the MRM run. In non-iterative MRM and single runs, values with an i flag are also cleared. You should be aware of this behavior if switching from iterative MRM to another mode.
Values set by the Iterative MRM “i” flag behave with output semantics. That is, they can be overwritten by any other value. In rulebased simulation, they are set when the controller is at priority zero, so values are given a priority of zero. Iterative MRM rules should only set values on data objects (typically integer indexed series slots as described at the end of this section), not simulation objects. Iterative MRM rules should be used to control the multiple runs; rulebased simulation rules within the run should be then used to set values on simulation slots that will actually be used in the run.
To configure an iterative run:
• Within the MRM Configuration dialog with the iterative mode, there is no Run Parameters tab. The iterative runs will begin at the start timestep of the model run. If users wish to change the model start timestep, this should be done in the single Run Control dialog.
• On the Iterative Runs tab are the following significant areas: the Pre-MRM Run Rules, the Post-Run Rules, the Continue After Abort toggle, Pre-Run Rule Execution Time, the Open Iterative MRM Rules Set button, and the Max Iterations selector.
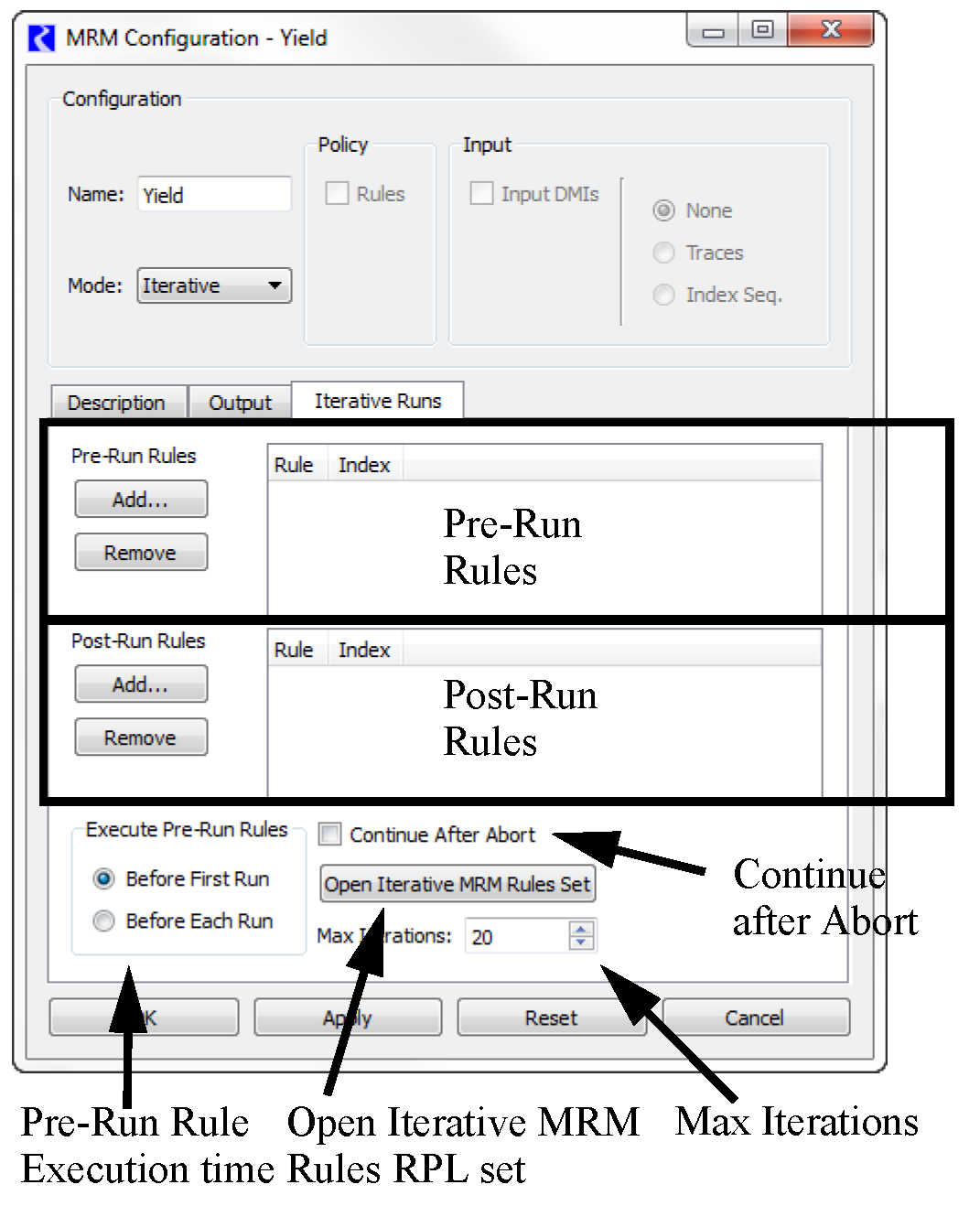
• Select Open Iterative MRM Rules Set button to open the Iterative MRM Rule set editor. This dialog operates very similarly to the standard RBS Ruleset Editor dialog. Create one (or more) Policy Group(s) and associated rules. The MRM Rules created are stored within the model file and may be available for use with any number of iterative MRM configurations. This set of rules can also be accessed from the workspace Policy, then Iterative MRM Rules Set.
• Once the MRM Rules have been built, return to the Iterative Runs tab of the MRM Configuration dialog. In this tab, the define which of the MRM rules should execute as part of the PreRun rules and which should execute after each iterative run, or both. These are defined in the appropriate areas using one of the following methods
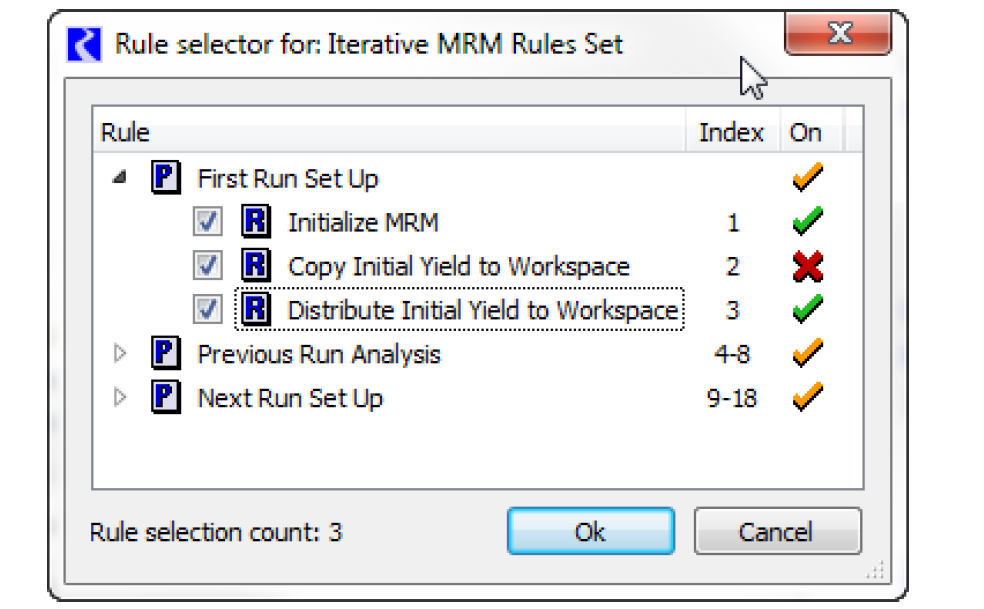
– Use the Add and Remove buttons. Select the Add button to bring up the Rule Selector as shown in the following figure. This dialog shows the rule groups in a tree view. Expand the tree-view to show individual rule names, their Index and their On status. Select the checkbox to check the desired rules. Select Ok to accept and return to the configuration dialog.
– Drag and drop rules from the MRM Ruleset to the Pre-Run Rules area or Post-Run Rules area.
Note: The order of addition into the display does not affect the rule ordering; the order is strictly consistent with priorities defined in the MRM Rules.
• To view a rule directly from the Iterative Runs tab, double-click the rule’s name to open the Rule Editor.
• Use the Execute Pre-Run Rules buttons to specify when Pre-Run Rules are executed:
– Before First Run. This is the default. Choose this option to execute the Pre-Run Rules before the first single run only, but not before subsequent runs.
– Before Each Run. Choose this option to execute the Pre-Run Rules before each single run.
• Consider activating the Continue After Abort option. If you want the Post-Run Rules to execute and possibly the next iteration to begin after an iteration is prematurely aborted (for any reason), select the checkbox.
• Select the Max Iterations selector and adjust it using the up and down arrows or by typing a value in the field to define the maximum number of iterations to run. Figure 3.3 shows a fully configured Iterative Runs tab.
Figure 3.3
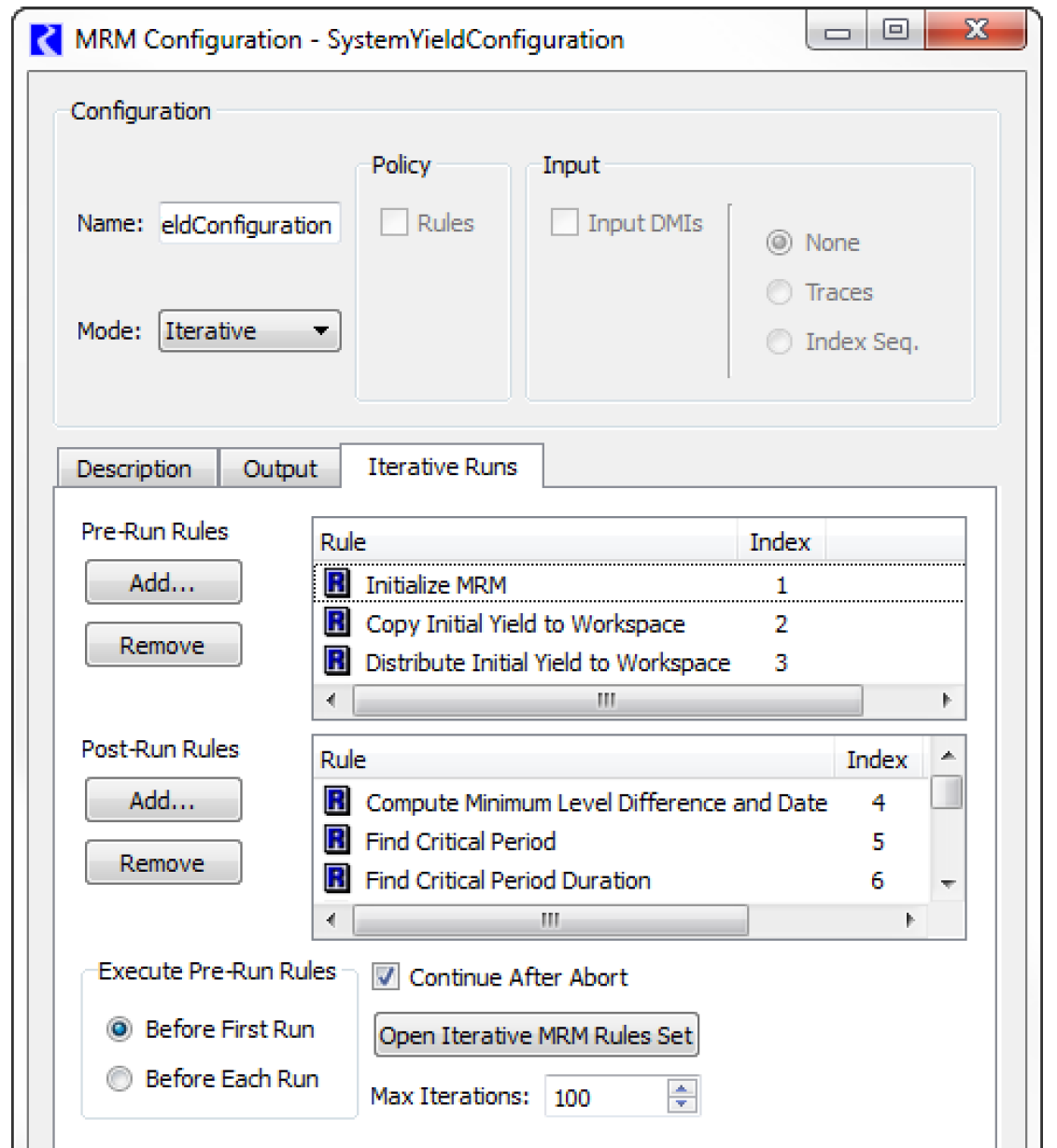
Note: The Post-Run Rules must make a significant change in values (for example, through a rule assignment or import of data through an input DMI) at the end of each run for the controller to make the next iteration. If the Post-Run Rules do not set any values, (possibly due to convergence) the controller will assume that the goal of the iterations has been achieved and stop.
Note: The MRM rules execute differently from the basic ruleset. When the MRM rules execute, each fires once and only once according to the execution order specified. There is no dependency functionality. In fact, they will all fire even if one of them aborts.
Integer indexed Series Slots work very well with Iterative MRM. Using these slots, you can store inputs, outputs, or intermediate results based on the index of the run. For example, after each iterative run, you could store the total volume of water released in an integer index slot in the row corresponding to the run index. At the end of the entire run, all of these volumes are stored and can be reviewed. The GetRunIndex predefined function can be used to get the index of the next iterative run. See Integer-indexed Series and Agg Series Slots in User Interface and GetRunIndex in RiverWare Policy Language (RPL) for details.
Policy
For concurrent and consecutive mode, rulesets can be specified for the runs. The policy setup of the configuration (None or Rules) must be selected from the Policy section of the MRM Configuration. Selecting Rules will enable the Rulebased Simulation controller when the multiple run is started. Rulebased multiple runs are runs in which there are one or more rulesets. You specify the ruleset to use for each run. Variations in rules can be a function of differences in content, priorities, or both.
• Select Rules under in the Policy section of the MRM Configuration and select the Policy tab.
• Append a new row for each additional ruleset by selecting the Plus button at the bottom.
at the bottom.
at the bottom.• Select the ruleset by selecting the File Chooser button  or double-click and type in the path name of the ruleset directly. This allows you to use environment variables in the path. Environment variables are prefixed with the “$”.
or double-click and type in the path name of the ruleset directly. This allows you to use environment variables in the path. Environment variables are prefixed with the “$”.
or double-click and type in the path name of the ruleset directly. This allows you to use environment variables in the path. Environment variables are prefixed with the “$”. • If necessary, remove a ruleset by selecting the Delete button  . There is no confirmation, but you can restore ruleset rows using the Reset button.
. There is no confirmation, but you can restore ruleset rows using the Reset button.
. There is no confirmation, but you can restore ruleset rows using the Reset button.In Figure 3.4, the first ruleset was specified by browsing to the C: drive, the second ruleset was specified by typing the path in directly and using the environment variable EISDIR
Figure 3.4
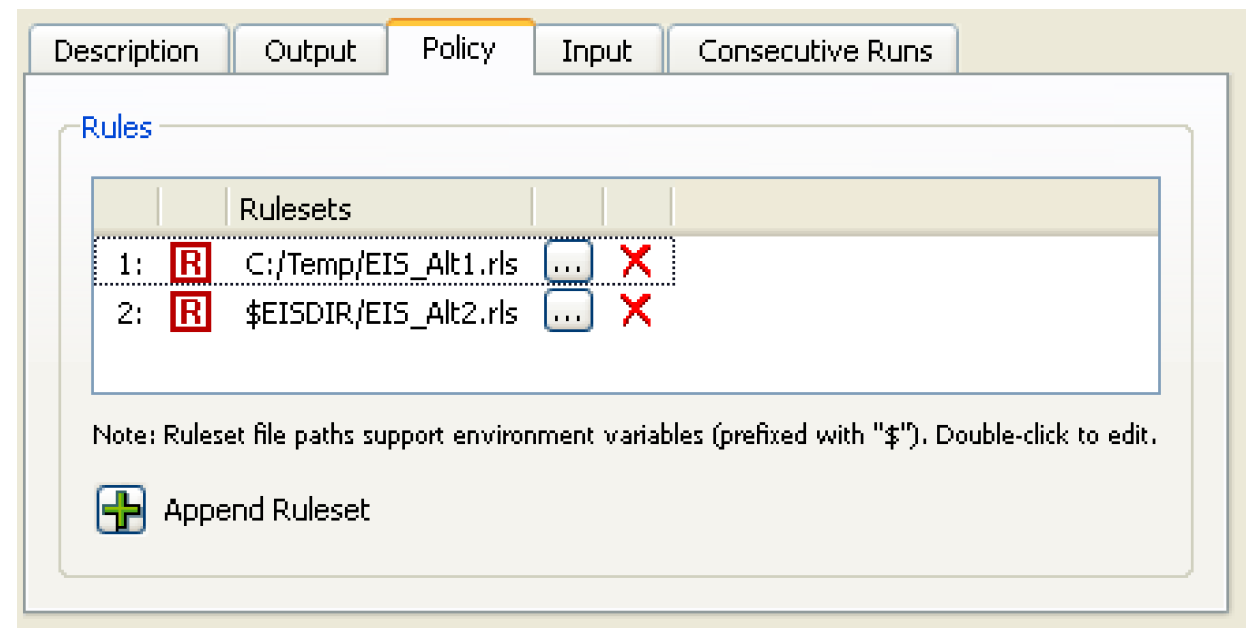
Note: The Policy tab is not applicable to Iterative MRM runs, but an iterative run can be a rulebased run where one ruleset is used for all iterations. It must be explicitly opened and loaded before the iterative run is started.
Note: Multiple rulesets in a single MRM configuration are not supported if using Distributed Multiple Runs; see Distributed Concurrent Runs for details.
Input
The inputs to the multiple runs are specified by selecting options in the top of the dialog and then specifying configuration details in the appropriate tabs.
• If the Multiple Runs use an Input DMI, select the Input DMIs checkbox in the Input section.
• Specify whether to use Traces, Index Seq., or None. See Index-sequential Runs for details on Index Sequential. See Input DMI Runs for details on traces.
Note: The Input section and tab are not applicable or available to Iterative runs.
Initialization DMI
You can optionally specify a single DMI or group that is invoked at the beginning of the multiple run. Select the Initialization DMI toggle to show the entry field. Type in the name of an existing DMI or use the  button to select an the DMI or group.
button to select an the DMI or group.
button to select an the DMI or group. 
Input DMI Runs
Input DMI runs vary the input data for a specified set of slots. For instance, ten runs might represent ten alternative release schedules for a reservoir. You specify the number of runs and a DMI for each run. The DMI loads the data into the model for each run. The DMIs must be previously defined in the RiverWare DMI interface.
• When the Input DMIs is selected on the MRM Configuration, on the Input tab, the Input DMIs section becomes active.
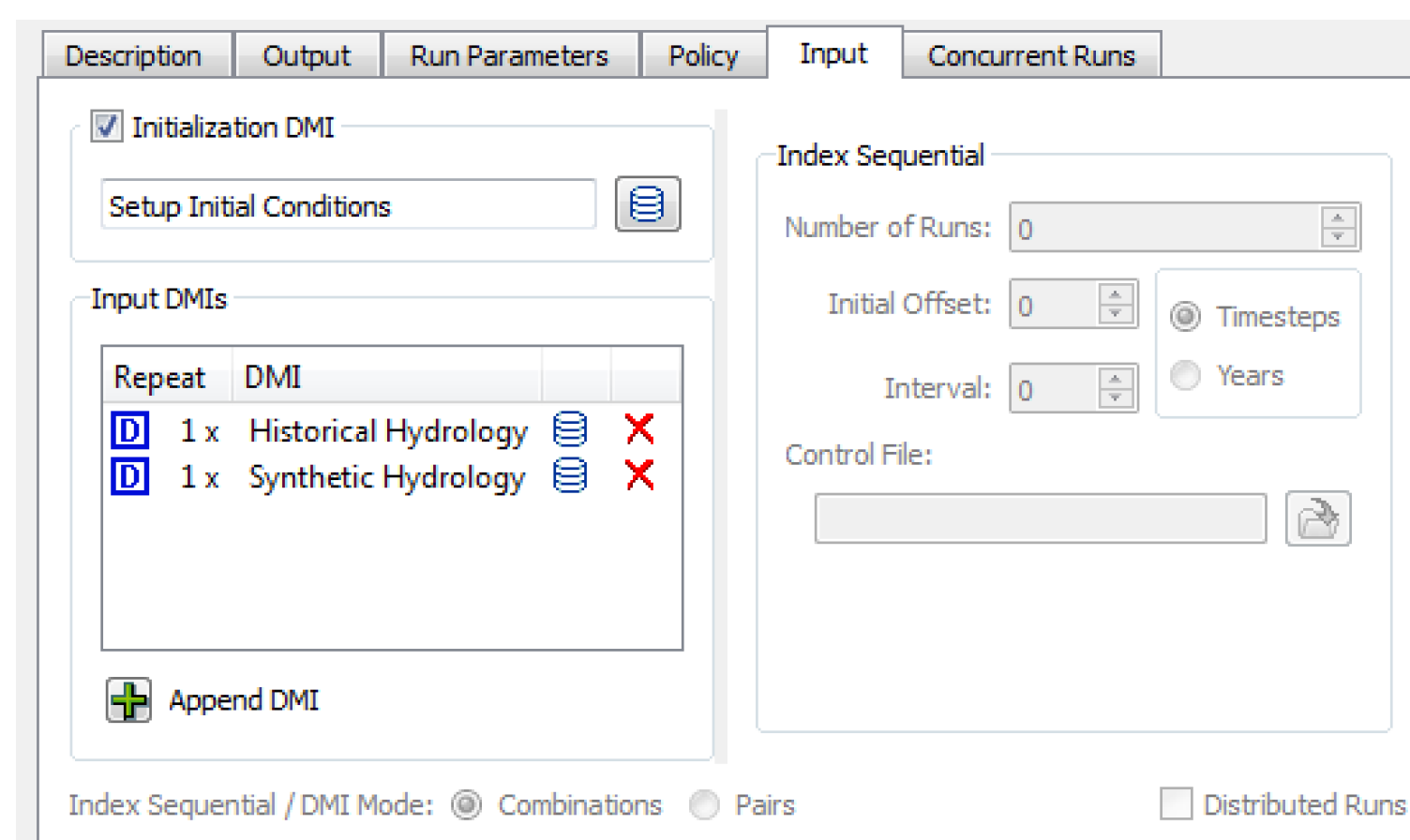
• Append a new DMI by selecting the Plus button at the bottom
at the bottom
at the bottom• Select the input DMI by selecting the DMI icon  and then choosing the previously configured DMI from the list.
and then choosing the previously configured DMI from the list.
and then choosing the previously configured DMI from the list.• If the DMI will be called more than one time, change the number in the Repeat column by double-clicking the cell and using the up/down arrows. DMIs might need to be called more than once in a MRM run, for example, with runs that execute multiple traces using the same DMI. In this situation, the DMI needs to be configured to make use of the trace number.
– For a Control File-Executable DMI, the executable should reference the last command line parameter passed from RiverWare:
-STrace=traceNumber
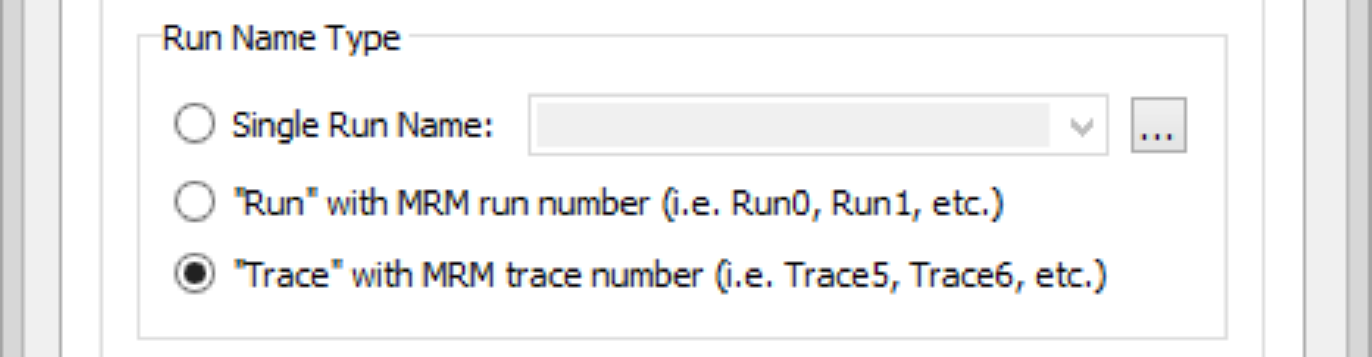
– For an Excel DMI, the Excel Dataset Run Name Type setting should use either the Run or Trace option; see Run Name Type in Data Management Interface (DMI).
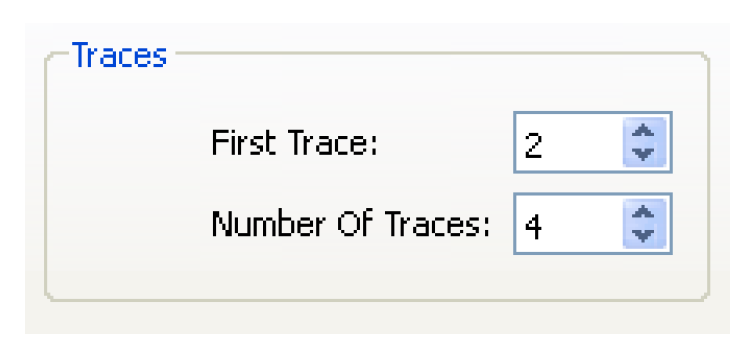
• If you are using Input DMIs but not using Index Sequential, you can choose the Traces option from the Input section on the MRM Configuration. This allows you to run only a portion of the runs specified by the Input DMIs. When Traces are specified, the Input tab shows the Traces area. In this area, you can specify
– First Trace
– Number of Traces
– To not run a subset of the runs, select None.
• If you wish to use Ensembles with HDB datasets, select the Input Ensembles checkbox. See Ensembles for details.
Index-sequential Runs
Index Sequential runs use an input time series which is systematically shifted between runs. You specify the number of runs, the interval (number of timesteps) by which the input data is shifted from one run to the next, and an initial offset (number of timesteps) by which data is shifted for the first run. The slots with input data to be shifted are identified by in a DMI control file. This type of run is typically used to perturb (shift) historical hydrologic data in order to be able to conduct statistical analysis of the results.
Note: Index Sequential is not applicable to Iterative or Consecutive runs.
Index Sequential specifies that, given a run start time, run timestep, run duration, number of runs, and time offset, input time series, a run can be systematically perturbed between runs. For example, if an Index Sequential run is defined as the following:
• input time-series:
• original value vector: 1, 2, 3, 4, 5, 6, 7, 8, 9
• original time vector: Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep
• offset: 4 timesteps
• interval: 1 timestep
• number of runs = 3
then, the following sequence of runs occurs:
• Run 1: Jan = 5, Feb = 6, Mar = 7, Apr = 8, May = 9, Jun = 1, Jul = 2, Aug = 3, Sep = 4
• Run 2: Jan = 6, Feb = 7, Mar = 8, Apr = 9, May = 1, Jun = 2, Jul = 3, Aug = 4, Sep = 5
• Run 3: Jan = 7, Feb = 8, Mar = 9, Apr = 1, May = 2, Jun = 3, Jul = 4, Aug = 5, Sep = 6
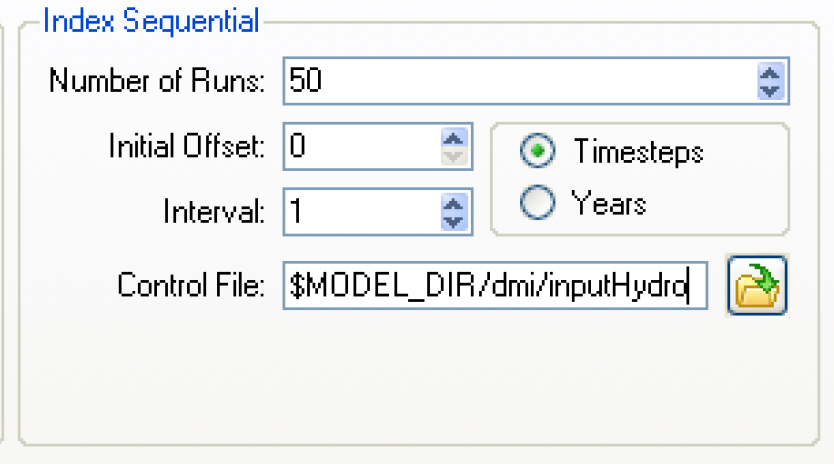
To setup an Index-sequential run:
• Select Index Sequential in the Input section of the MRM Configuration and select the Input tab.
• Specify the Number of Runs by typing in the value or by toggling the up/down arrows.
• Specify the Initial Offset by typing in the value or by toggling the up/down arrows.
• Specify the Interval by which the data is shifted from one run to the next by typing in the value or by toggling the up/down arrows in the Interval field.
• Specify the units for the Initial Offset and Interval as Timesteps or Years.
• Specify the Control File by typing in the path directly or by using the file chooser to select it. Typing in the path and name directly allows for the use of environment variables. Take care to spell the entire path correctly. The control file specifies the slots that will be rotated for each run. It uses the same format specified, but no file name or keyword value pairs are necessary. Typically, it is just the object and the slots that are specified. See Control File in Data Management Interface (DMI) for details.
• On the Concurrent Runs tab, the combinations of policy sets and Input DMIs are set up for the index sequential run.
• Select the Show Index Sequential checkbox at the top of the Concurrent Runs tab to view each index sequential run listed individually.
Combined Runs
By default, the runs that are made in concurrent MRM are a multiplicative combination of inputs. This set is called Combined Runs. Combined runs are defined as the Cartesian product of all the involved base-type runs. For example, a combined run consisting of two rulesets and four Input DMIs, results in 2 * 4 = 8 model runs.
The order in which individual runs within a combined multiple run are executed is determined by the precedence level of each mode. Order of precedence (from highest (1) to lowest (3)) is as follows:
1. Input DMI runs,
2. Rulebased runs, and
3. Index-Sequential
Elements of lower precedence iterate before elements of higher precedence. For example, in case of a combined run containing two Input DMI runs and two Rulebased runs, the following sequence of four runs is made:
1. Input DMI 1 & Ruleset 1.
2. Input DMI 1 & Ruleset 2.
3. Input DMI 2 & Ruleset 1.
4. Input DMI 2 & Ruleset 2.
Thus, the default combinations mode results in the total number of runs equal to the product of the number of policy sets, the number of input DMIs, and the number of index sequential runs:
#of MRM runs = #of Policy Sets * #of Input DMIs * #of Index Seq Runs
In very specific circumstances, it is possible to alter the mode of how many MRM runs result from the combination of input DMIs, policy sets, and Index Sequential runs. If Index Sequential has been selected and there are as many (or more) Input DMIs as Index Sequential runs and there are zero or one rulesets selected, then it is possible to choose either Combinations or Pairs in the Index Sequential / DMI Mode selection.
The Pairs mode results in the total number of runs equaling the number of pairs of Input DMIs and Index Sequential runs. If the number of input DMIs does not match the number of Index Sequential runs, then the number of index sequential runs equals the total number of possible pairs, (i.e., the minimum of the number of input DMIs and the number of Index Sequential runs). The Pairs mode is necessary to run the CRSS Lite model.
# of MRM runs = min(# of Input DMIs, # of Index Seq Runs)
When the pairs mode is specified, the runs can be distributed to multiple processors. See Distributed Concurrent Runs for details.
Ensembles
An ensemble contains a set of traces where each trace represents the data for one run of the multiple run. An ensemble of trace data can function as input to the runs of a multiple run, or can represent output from a multiple run. An ensemble can have metadata that describes the overall ensemble and metadata that describes each of the individual traces.
Note: Currently only HDB datasets in Database DMIs can be configured to function as ensembles.
Ensemble Configuration
To utilize ensembles, on the Input tab of the MRM configuration, select the Input Ensemble checkbox. This will disable Input DMIs, Traces, and Index Sequential functionality as the ensembles will determine the number of runs in the multiple run.
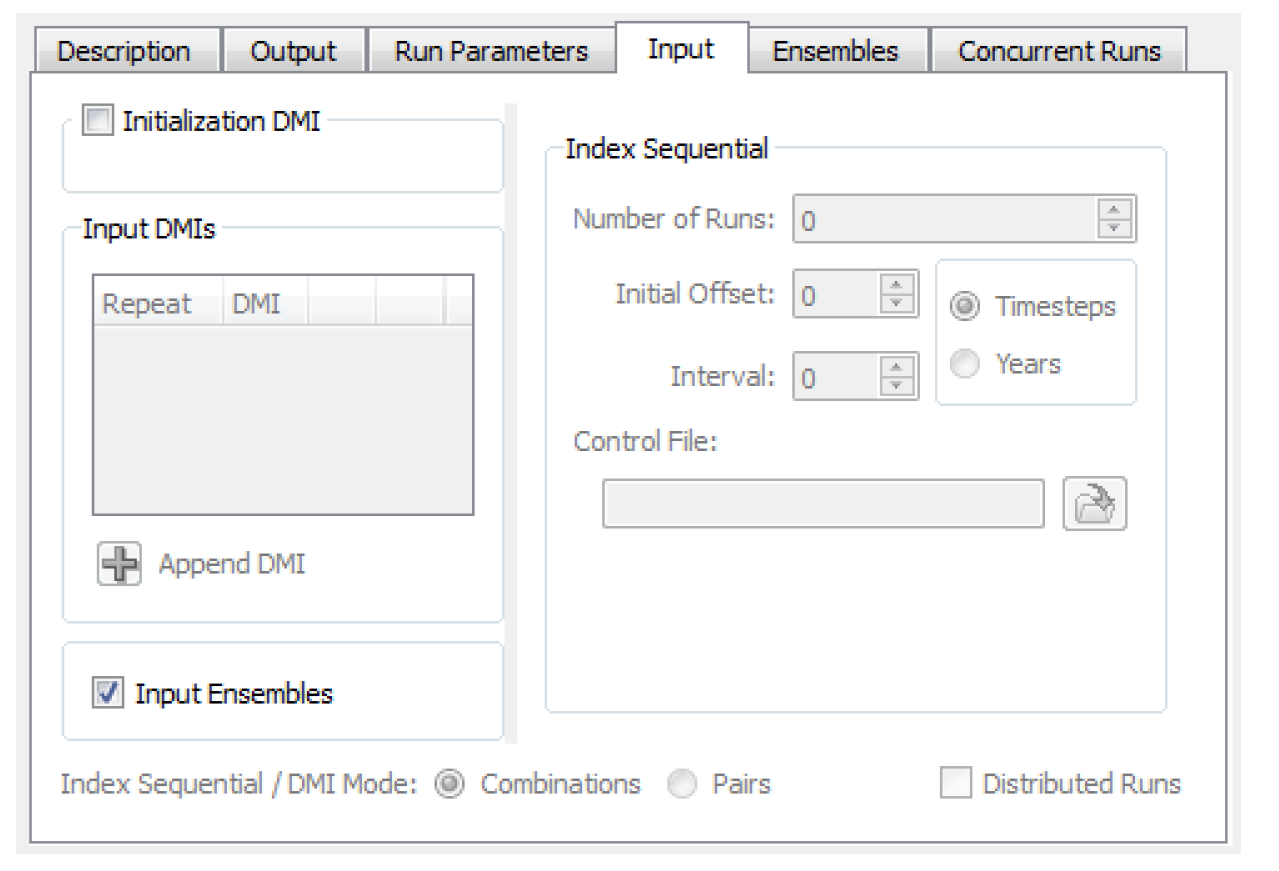
When you select the Input Ensembles toggle, an Ensemble tab is added to the dialog where input and output ensembles are specified.
Select the Plus in the Input Ensembles frame to open a list of input DMIs defined in the model. You can select one to add as an ensemble. Only valid input DMIs with datasets configured with ensembles can be added.
Note: Currently only HDB datasets in Database DMIs can be configured to function as ensembles. See HDB Table Type—Ensembles in Data Management Interface (DMI) for details.
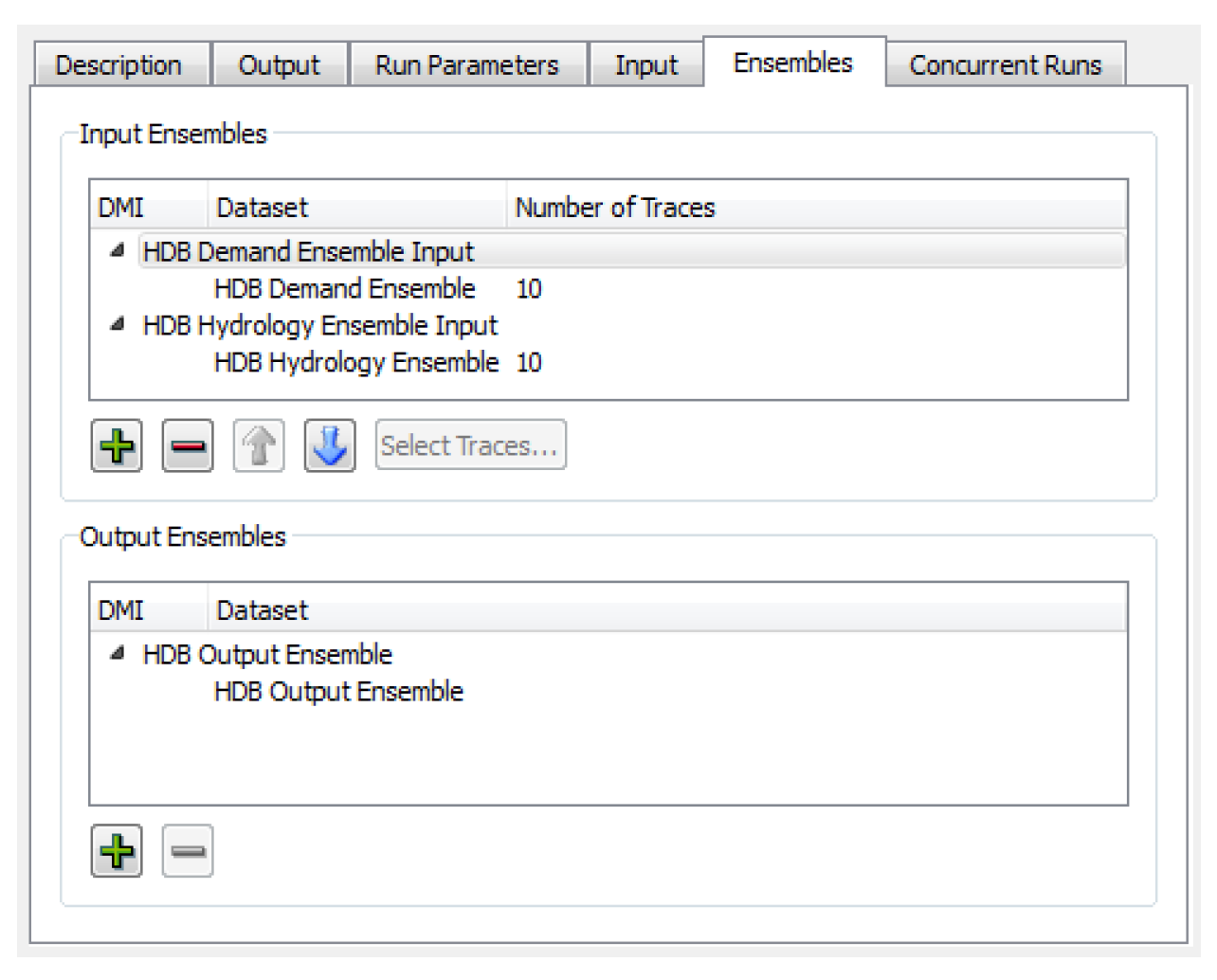
Input DMIs will be executed in the order shown. This allows you to configure how data is loaded if the same slots are used in multiple input DMIs (the last one in wins). Use the up and down arrow buttons to reorder the selected DMI.
When a DMI is added as an input ensemble, it defaults to using all of the traces defined in the ensemble. The number of traces is shown for the DMI, or for its datasets in the case of database DMIs, as a column in the dialog. When an item having traces is selected in the list, the Select Traces button is enabled. Select this button to open a dialog showing all of the traces for the ensemble. Choose a subset of traces as desired.
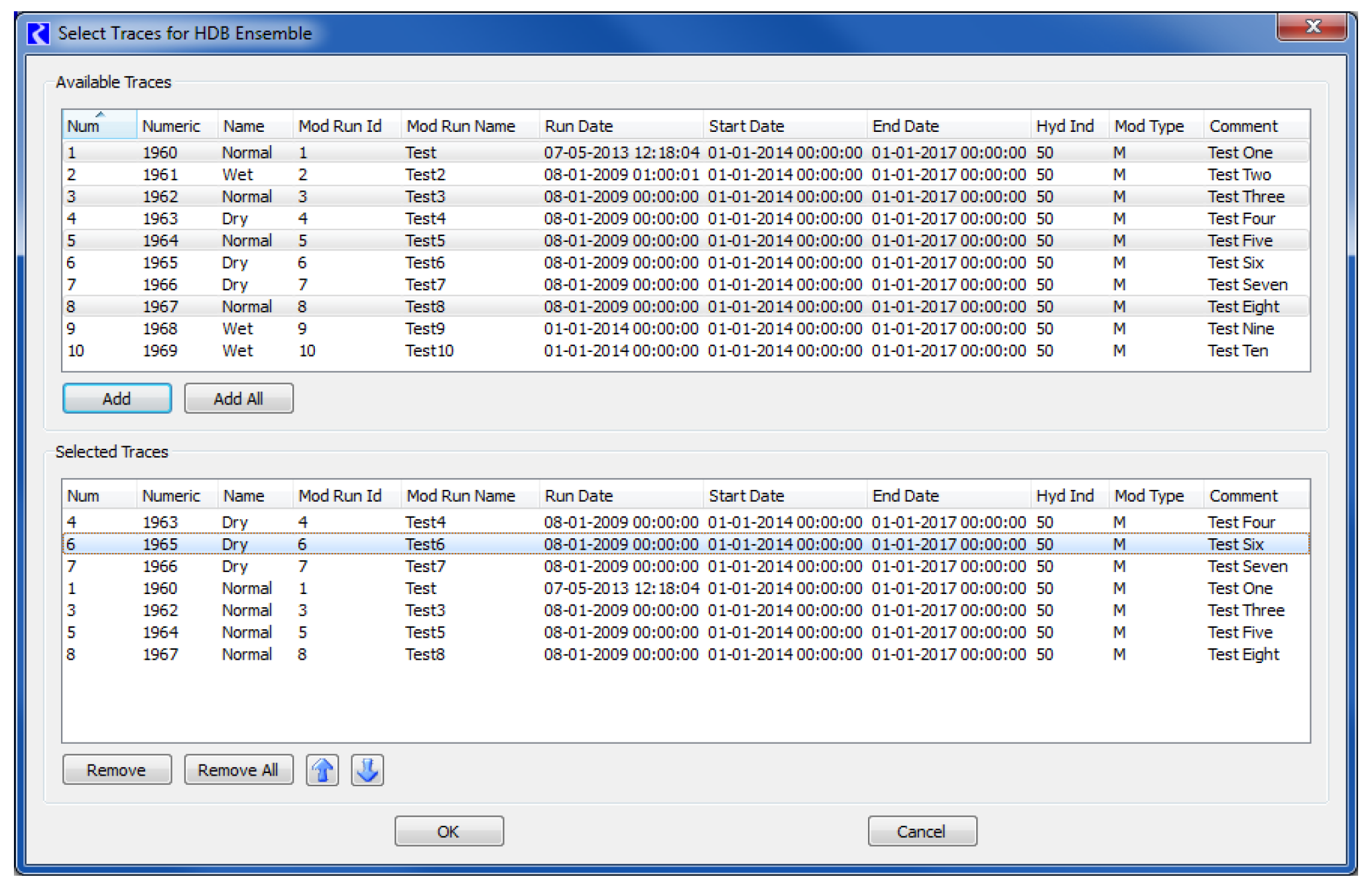
All available traces are presented in the upper list. When added using the Add or Add All buttons, they are copied to the lower list showing the selected traces. Traces can be removed from the selected list with the Remove or Remove All buttons. The selected traces can be ordered using the up and down arrow buttons. With these controls, a subset of traces in the ensemble can be chosen and used in any order as input to the multiple run. When applied with the OK button, the number of selected traces will now appear in the Number of Traces column in the Input Ensembles frame of the Ensemble tab.
The number of traces for input ensembles must match across all of the input ensembles because the number of traces input to the multiple run will determine the number of runs. If an MRM configuration with differing numbers of input ensemble traces is applied or a run is started, an error message is generated.
HDB ensemble datasets have an option to defer picking an ensemble for the dataset until the MRM run is started. See HDB Table Type—Ensembles in Data Management Interface (DMI) for details. In this case, the Number of Traces column will show a zero, and using the Select Traces button will return a message that the ensemble will not be selected until MRM start. Where datasets of this type are used in input ensembles, the number of runs in the multiple run cannot be determined until the MRM run is started, so the Concurrent Runs tab of the MRM configuration dialog will be empty. Uniformity of number of traces across input ensembles is checked after ensembles are selected at the start of the MRM run.
DMIs to use as output ensembles are added and removed with the plus and minus buttons in the Output Ensembles frame of the Ensembles tab. Unlike input ensembles, the order of output ensembles does not matter, so there are no ordering controls in this frame. All existing data and metadata in output ensembles for a multiple run are cleared at the beginning of the multiple run. At the end of each run in the multiple run, the data specified in output ensemble DMIs are written to the trace of the output ensemble that corresponds to that run. An output ensemble must have at least as many traces as the number of runs in the multiple run so that all of the run data can be written. If an HDB dataset configured to select the ensemble at MRM start is used in an output ensemble, its number of traces is checked after the ensemble is selected.
Ensemble Metadata
An ensemble can have metadata that describes the ensemble as well as metadata that describes each trace in the ensemble. Metadata is represented in RiverWare as Keyword/value pairs, such as “comment”/”Climate Change Hydrology”. An important functionality of ensembles with MRM is that the ensemble and trace metadata from input ensembles are combined and copied over to output ensembles.
For ensemble metadata, values for the “domain”, or “comment” keywords from input ensembles are concatenated with semicolons and written as values for these keywords to output ensembles. For example, if there were two input ensembles, one with a comment “Historic Hydrology” and the other with a comment “High Projected Demand”, an output ensemble would be given the comment keyword value of “Historic Hydrology;High Projected Demand”. Values for other ensemble metadata keywords are not concatenated. If values for these other keywords differ among input ensembles, the keyword value from the first ensemble is copied to the output ensemble and a warning issued that values for this keyword differ among the input ensembles.
For trace metadata, values for the “name” keyword for multiple input ensemble traces will be concatenated with semicolons and written as the value for the “name” keyword to an output trace. Values for other trace metadata keywords are not concatenated. If values for these other keywords differ among multiple input ensemble traces, the keyword value from the trace of the first ensemble will be copied to an output ensemble trace and a warning issued that values for this keyword differ among the input ensemble traces.
See HDB Table Type—Ensembles in Data Management Interface (DMI) for details on HDB ensembles and metadata.
Output
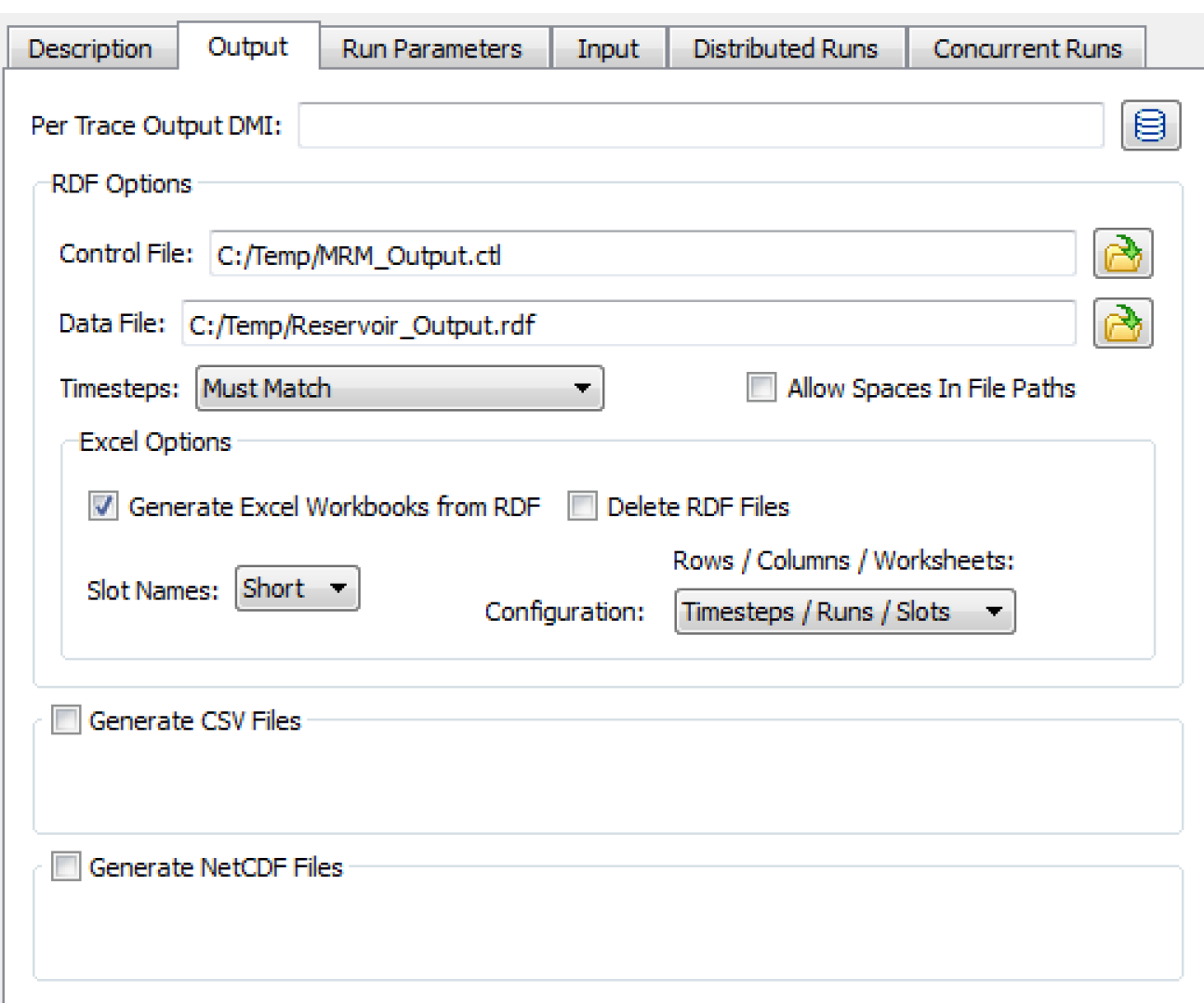
During a multiple run, output can go to an output DMI and/or one or more RiverWare Data Format (RDF) text files. Options are also available to send output to CSV files or NetCDF files. Select the Output tab of the Multiple Run Editor. The following are configuration options:
DMI
The optional Per Trace Output DMI field allows selecting or entering an output DMI or a group of output DMIs that will be run after each single run of the multiple run. HDB ensemble datasets cannot be used in these DMIs, but rather must be used in the MRM ensemble configuration; see Ensemble Configuration for details.
The DMIs must be previously configured in the DMI Manager in RiverWare. The executable that is configured for the DMI can reference the trace number of the run that is outputting by referencing the last command line parameter passed from RiverWare:
-STrace=traceNumber
Note: Using a Per Trace Excel Output DMI in combination with Distributed MRM is not recommended. In that case, multiple RiverWare processes can end up trying to write to the same Excel file simultaneously, which may cause a conflict. See Distributed Concurrent Runs for details.
RDF
Configurations for RDF output from MRM include the following:
Control File
Type or use the File Chooser button to select a complete file path into the required control file field. The control file is used to specify which slots are output after each MRM run. The control file may contain “file =” specifiers for any line entries in the file. This causes data associated with those lines to go to the specified RDF output file. In the example control file below, if “fileName” is the same for each slot, then the output will go to a single RDF file; varying fileNames will send the output to multiple RDF files.
MountainStorage.Inflow: file=fileName
MountainStorage.Outflow: file=fileName
MountainStorage.Storage: file=fileName file=fileName2
You can optionally specify multiple files for a single slot as in the third line above. Also, slots with a timestep different than the model’s timestep can be output using the same syntax.
In the control file, there are four ways to specify where the data files are created:
• Hard code the path: file=C:/DMI/Data/ResA.Inflow
• Use an environment variable: file=$(DMI_DATA)/ResA.Inflow
• Use '~': file=~/ResA.Inflow where '~' is replaced with $RIVERWARE_DMI_DIR/<DMI name>
• If the filename is not specified, the output file will be created in the directory in which RiverWare resides.
The second option is recommended as it is more transparent than '~” but still allows the model to be moved from machine to machine by setting the environment variable to the appropriate value on each machine.
Tip: See RDF Viewer for more information on quickly viewing the results of an MRM run using the RDF Viewer.
Timesteps
Specify whether RDF output files may contains slots whose timesteps differ. There are three choices:
• Must Match. All slots written to an RDF file must have the same timestep. Slots whose timesteps differ from the file’s timestep are skipped. (The file’s timestep is determined by the first slot MRM associates with the file.) You are warned about slots being skipped, and asked whether to continue the MRM run.
• Use Smallest. Slots written to an RDF file may have different timesteps, with the output written using the smallest timestep.For example, if slots with 1 Month and 1 Year timesteps are written to an RDF file, monthly values will be written and the 1 Year slots will write 11 NaN followed by a value.
• Use Largest. Slots written to an RDF file may have different timesteps, with the output written using the largest timestep. For example, if slots with 1 Month and 1 Year timesteps are written to an RDF file, yearly values will be written and the 1 Month slots will write December values.
Data File
Optionally type or use the File Chooser button to select a complete file path into the Data File field. This file is used as the RDF output file for any lines in the control file that do not have an explicit file specifier. If the data file field is used and there are no “file=” specifiers in the control file, then all output will go to this single data file.
Excel Options
Select Generate Excel Workbooks from RDF to create Excel files from all of the RDF output files after all runs have completed.
Select Delete RDF Files to delete all RDF files after the Excel files are created. (The separate RdfToExcelExecutable program contains the same functionality for creating Excel files from RDF files and can be used outside of RiverWare to process RDF files from an MRM run.)
Select a Configuration from the menu to control how timestep, slot, and run data from RiverWare are mapped onto the Excel dimensions of rows, columns, and worksheets.
Select an option from the Slot Names menu to specify how slot names are written into the Excel workbook. Options are as
• Index: (Slot0, Slot1, etc.)
• Short: Automatically shortened names (lower case vowels removed)
• Full: Full slot names (limited to 31 characters for worksheet names, which is the limit for Excel)
CSV Files
CSV files can be generated from the MRM run outputs. The CSV files are formatted for direct use within Tableau data visualization software. The configuration allows for the selection of various pieces of information to be used as dimensions in Tableau. The CSV output is essentially a table with the columns delimited by commas.
1. Near the bottom of the Output tab in the MRM configuration dialog, select the checkbox for Generate CSV Files.
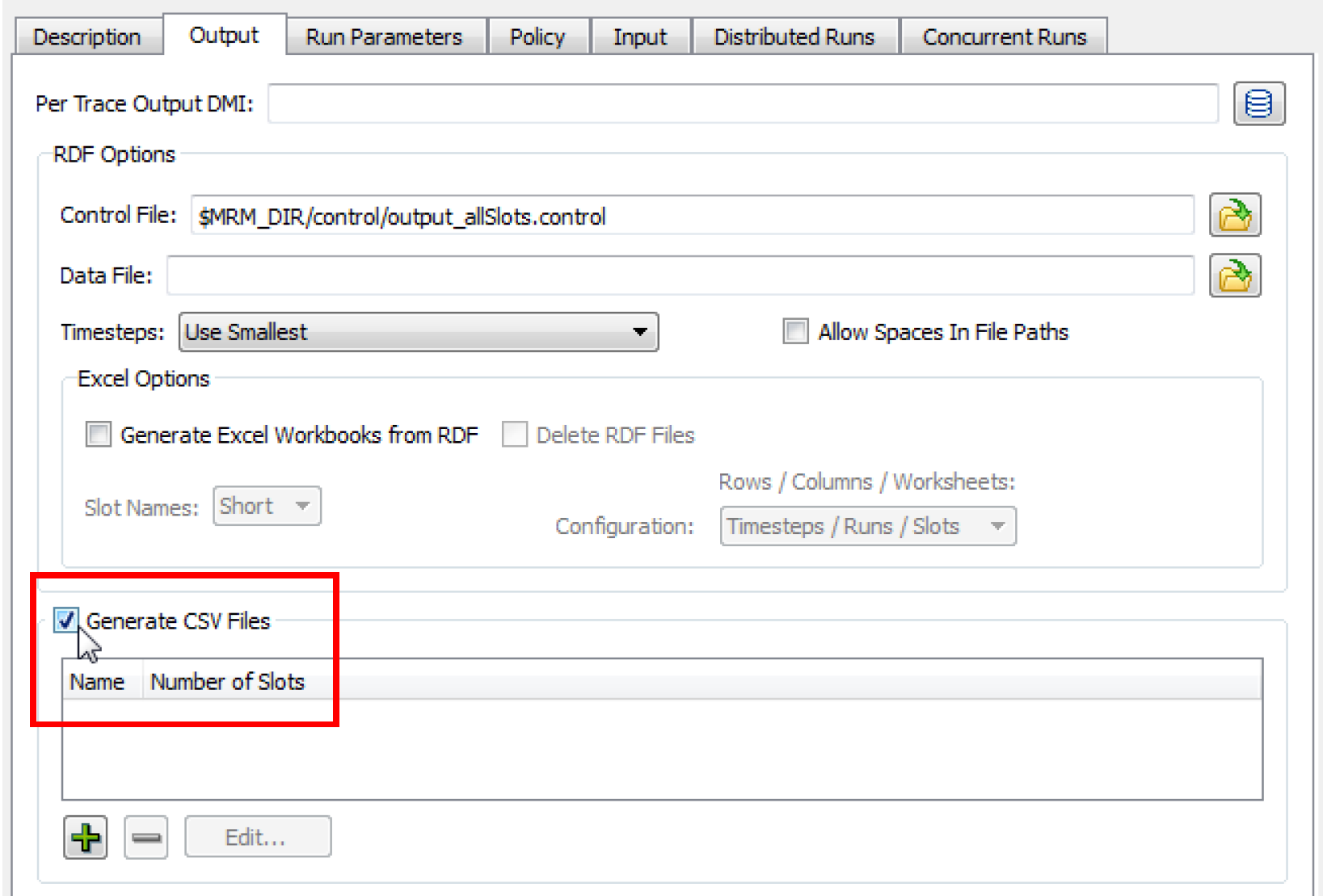
2. Select the Plus sign to add a new CSV output file. Then select Edit to configure its contents. This will open the CSV File Configuration dialog.
3. The CSV can then be given a name to display in the list in the MRM configuration.
4. In the File field, either select a CSV file to which the new outputs should be written by selecting the Select button, or type in a complete file path. Environment variables can be used in the file path preceded by a “$”.

5. Next, select which pieces of additional information should be included as columns in the output table by selecting or clearing the checkbox by each optional element. Figure 3.5 shows the list of available elements. The CSV output file will contain a column for each item selected. The text shown in the CSV File Configuration dialog will be used as the column header. The Slot Value column is the only column that will contain true “output” data from the MRM run. The Slot Value will be considered a “measure” within Tableau. The remaining columns contain information associated with each Slot Value and will be considered dimensions within Tableau.
Figure 3.5
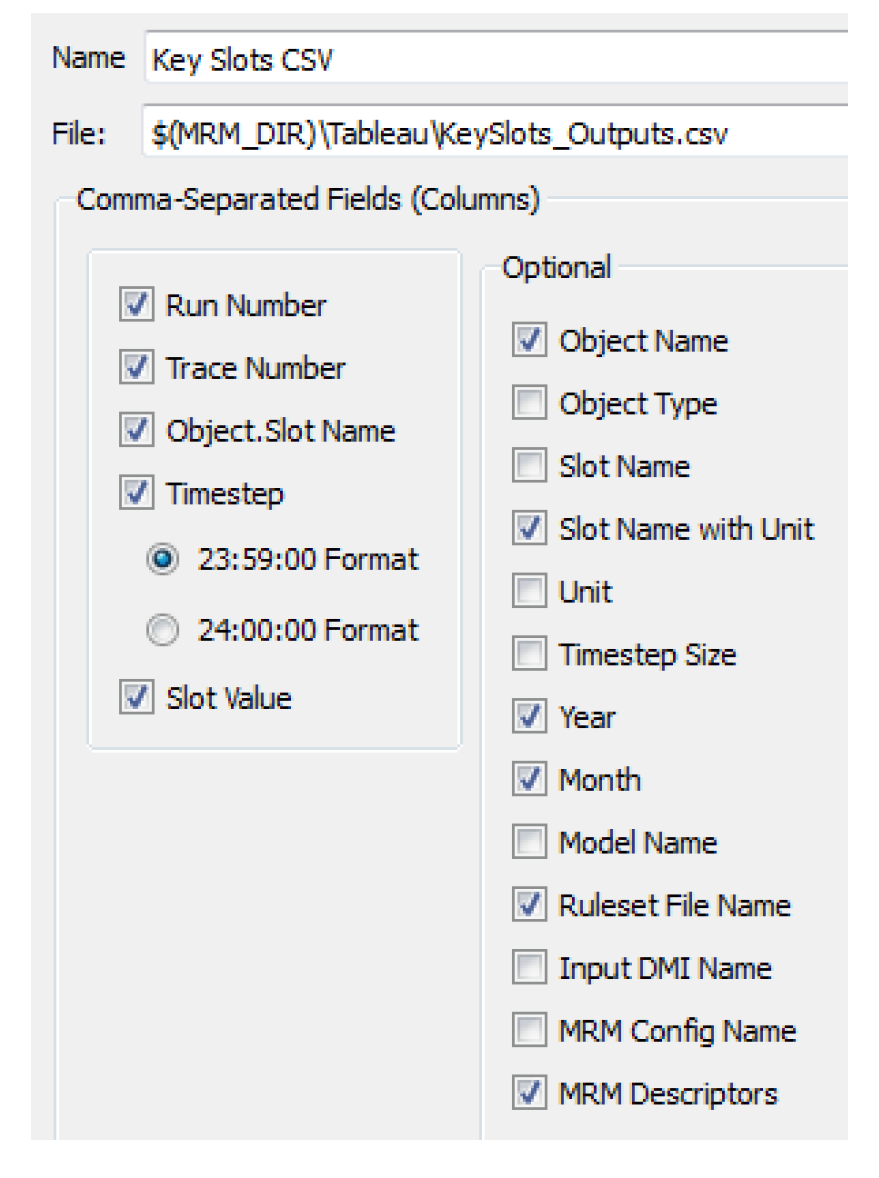
Note: In the context of Distributed Multiple Runs the Run Number corresponds to the run number on the individual processor. Thus if there are eight runs distributed to four processors (two each), all rows in the resulting CSV file will show a Run Number of either 1 or 2.
6. Then add slots to the CSV output by selecting Plus sign below the Slots panel. This will open a slot selector dialog, which can be used to add the desired slots. A slot can be removed from the selection by selecting it in the list to highlight it, then selecting the Minus sign.
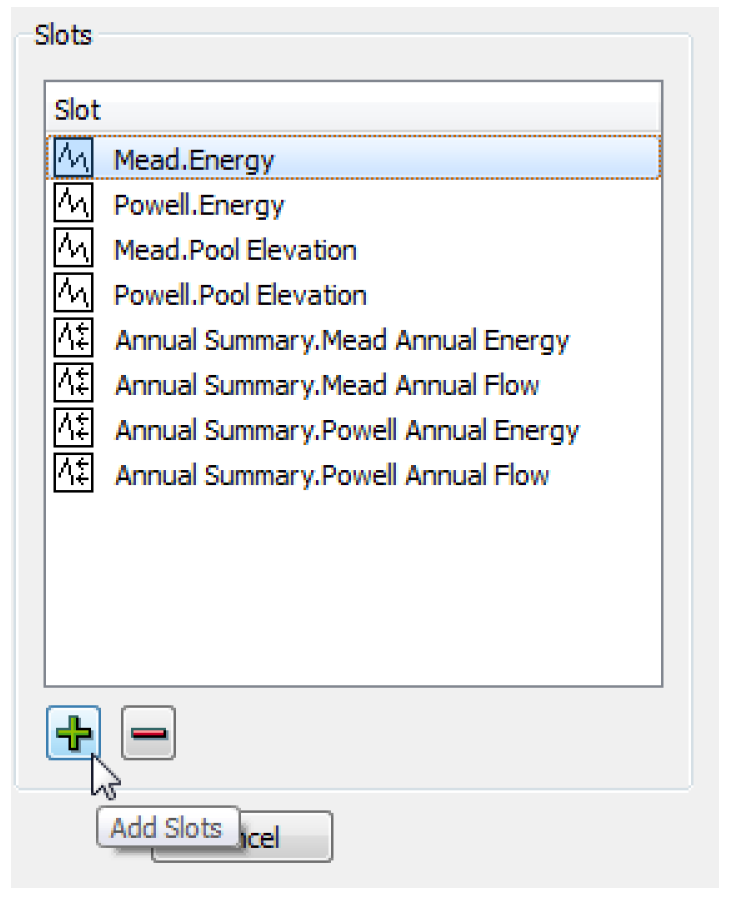
7. After configuring the CSV output, select OK in the CSV File Configuration dialog, and select Apply or OK in the MRM Configuration dialog to apply the changes.
During the MRM run, RiverWare will write the outputs to the specified CSV file. The file will contain one row for each selected slot at each timestep for each run. For each row, the columns will be filled in appropriately by RiverWare based in the selected dimensions. Figure 3.6 shows part of a sample CSV output file (viewed in Microsoft Excel).
Figure 3.6
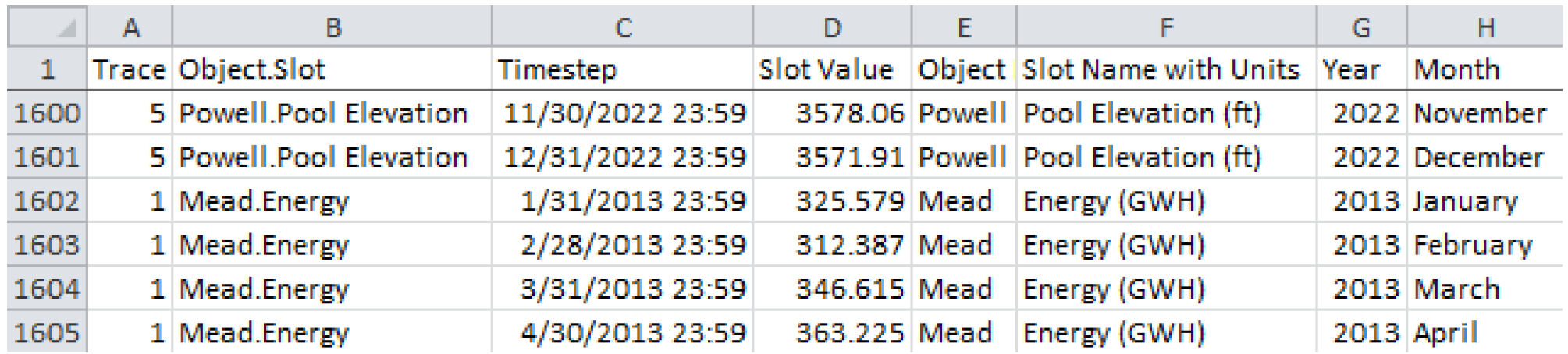
RiverWare uses end of timestep format for all datetime references. Thus for a 1 Month timestep, July 2014 would be fully specified as 7/31/2014 24:00. Tableau and Excel do not have a concept of 24:00 as a time but would instead use 8/1/2014 00:00 for the same point in time. Therefore with the proper timestep option selected in the dialog, one minute is subtracted from all timestep values (e.g. 7/31/2014 23:59) to assure that they appear with the appropriate day and month references in Excel and Tableau.
Note: If the specified CSV file already exists, the CSV output from the new MRM run will overwrite the existing CSV file. It will not append data to the existing file.
NetCDF Files
Network Common Data Format (netCDF) files can be generated from the MRM run outputs. The configuration allows for the selection of various pieces of information to be used as global attributes and slot (variable) attributes. Time and Traces are treated as dimensions.
Note: RiverWare will write the file in the netCDF-3 format, with one unlimited dimension (time). The output does not use any of the features available in netCDF-4 and testing has shown that netCDF-3 provides a much smaller file size than using netCDF-4.
1. Near the bottom of the Output tab in the MRM configuration dialog, select the checkbox for Generate NetCDF Files.
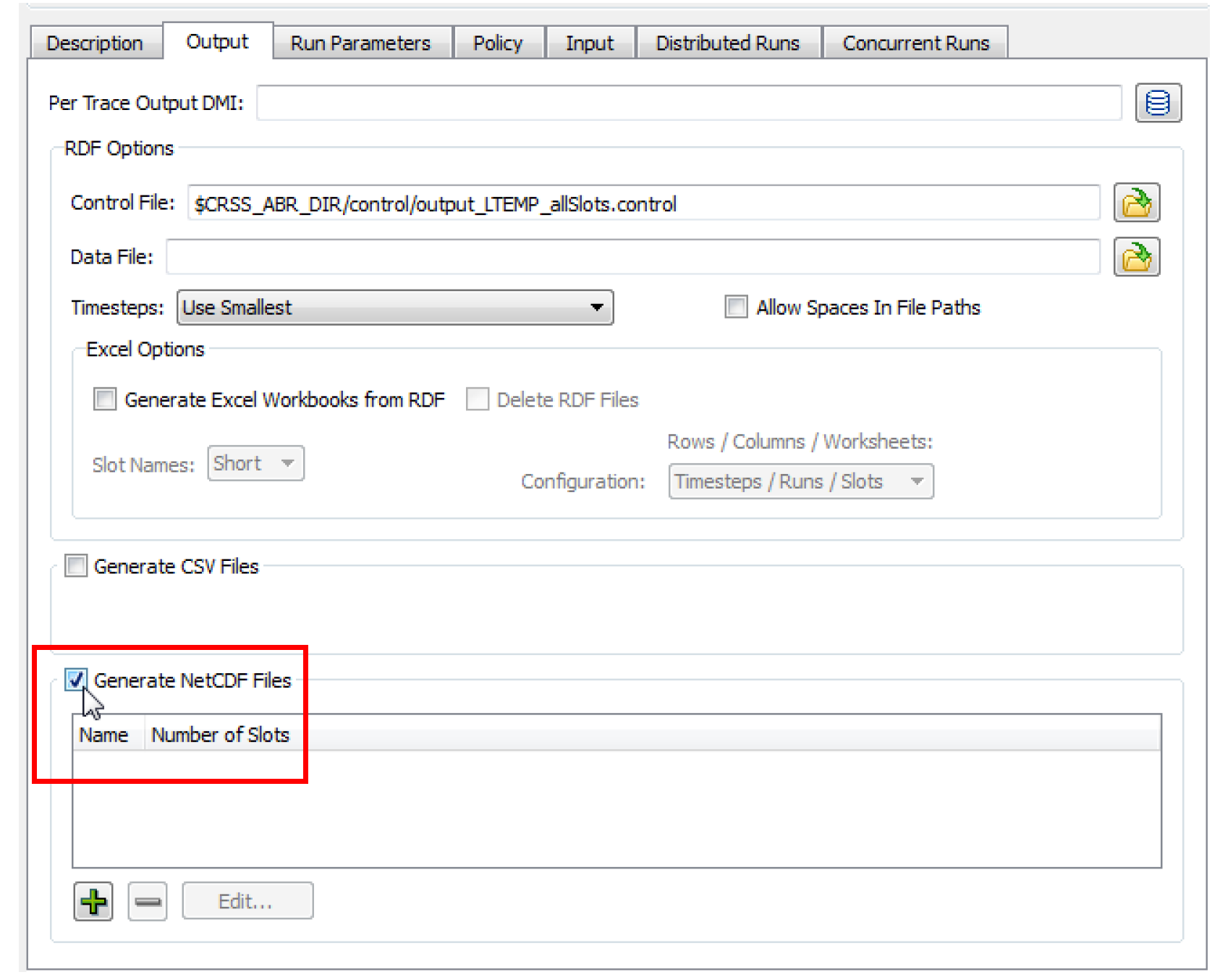
2. Select the Plus sign to add a new netCDF output file. Then select Edit to configure its contents. This will open the NetCDF File Configuration dialog.
3. The netCDF file can then be given a name to display in the list in the MRM configuration.
4. In the File field, either select a netCDF file to which the new outputs should be written by selecting the Select button, or type in a complete file path. Environment variables can be used in the file path preceded by a “$”.

5. Next, optionally select global attributes and slot attributes to be included with the outputs by selecting or clearing the checkbox by each element.
Note: Time (timestep) and Traces (Trace Number) will automatically be used as dimensions in the netCDF output.
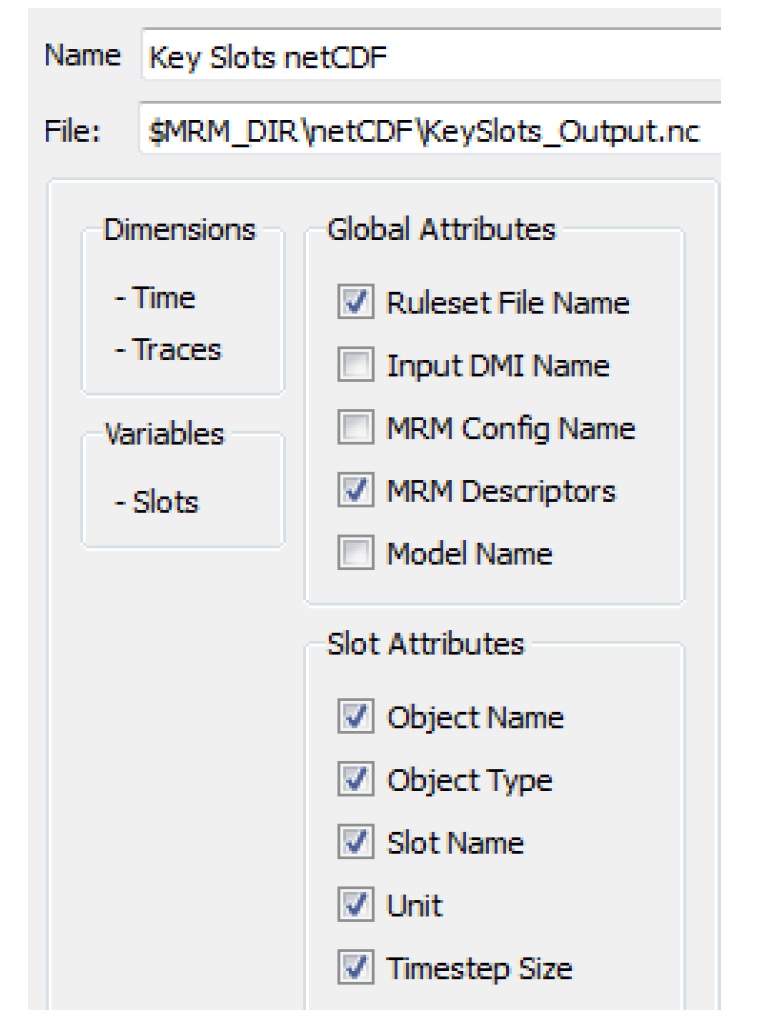
6. Then add slots to the netCDF output by selecting the Plus sign below the Slots panel. This will open a slot selector dialog, which can be used to add the desired slots. A slot can be removed from the selection by selecting it in the list to highlight it, then selecting the Minus sign. The Object.Slot name will be used as the variable name in the netCDF file.
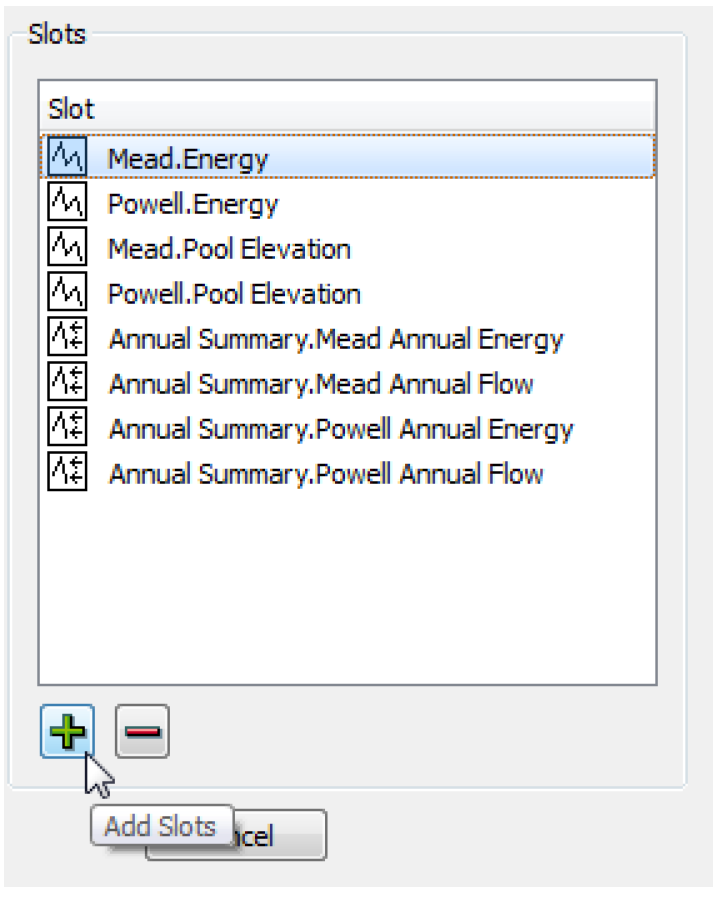
7. After configuring the netCDF output, select OK in the NetCDF File Configuration dialog, and select Apply or OK in the MRM Configuration dialog to apply the changes.
Revised: 12/01/2020