
Steps
Given a working model for a basin, to conduct a reservoir yield study, the following changes need to be made.
1. Import the yield study data object.
– Select the workspace menu item Workspace, then Objects, then Import Objects and import the file YieldStudy.obj.This will create a new data object named Yield Study Data.
The slots on this object used for input data are as follows.
– Reservoir Data for Bisection. The name of the reservoirs which are participating in the yield study should appear as the row labels of the Reservoir Data for Bisection Table Slot. Append rows as necessary using the Edit menu. Edit the row label as appropriate using the View, then Edit Row Labels menu. When editing row Labels, there is a useful button in the Edit Row Labels dialog to Set Label(s) to an Object Name. The yield study ruleset requires a lower limit on the yield for each individual reservoir. By default the algorithm will use 0.0cfs as the lower limit. If this is not a reasonable lower limit, you can provide an alternative value in the Minimum Yield column of the table. The yield study ruleset also requires an upper limit on the yield for each individual reservoir. By default it will use the average inflow, over the run, for each reservoir. If this is not a reasonable upper limit, you can provide an alternative value in the Maximum Yield column of the table. For certain algorithms, an Initial Yield to Try can be provided as a column.
– Convergence From Above, Convergence From Below. The scalar values representing how accurate the yield value should be above or below the exact answer: Convergence From Above and Convergence From Below.
– Yield Distribution. This optional periodic slot is used to specify factors for distributing the average yield throughout the year. The values in the slot are the fraction or percentage of the average yield to be applied to each timestep in the run. The values in this slot should average to 1.0 over the course of a year. A prerun rule will check that they average to 1.0 and stop the run if they do not. If this slot is to be used, makes sure to use the MRM rule Use Distribution Pattern. See Step 4., below.
• The remaining slots on this data object contain output values from the yield study. Most of them are indexed by the MRM run number.
– Yield. Integer indexed series slot contains the results of the analysis (indexed by the MRM run number). Append columns as necessary using the Edit menu. On the Yield slot, modify the column label (using the View, then Edit Column Labels menu) to match the reservoir's name. When editing column Labels, there is a useful button in the Edit Column Labels dialog to Set Label(s) to an Object Name.
– Reservoir Index. Integer indexed series slot that tracks which reservoir is being analyzed (indexed by the MRM run number). In a single reservoir study, this value will always be output as zero.
– Yield Upper Bound, Yield Lower Bound. Integer indexed series slots indicating the bounds used for the current iteration by the bisection method on the current reservoir (indexed by the MRM run number).
– Minimum Level Difference. Integer indexed series slot showing the minimum difference between pool elevation and the bottom of the conservation pool for the current reservoir at the current run (indexed by the MRM run number).
– Minimum Level Difference Date. Integer indexed series slot containing the date at which the Minimum Difference occurs.
– Critical Period Start Date, Critical Period End Date, and Critical Period Duration. These integer indexed slots have a unit type of DateTime. They are used to store the dates when the critical period starts, ends, and the duration, respectively.
– Estimated Yield Error. Integer Indexed series slot containing the underestimation error associated with the yield. This is calculated as the additional volume of water that must be released during the critical period, including an estimate of reduced evaporation, to lower the pool to the bottom of conservation pool on the critical date. See Algorithms for details on this calculation.
– Distribute Yield. Integer Indexed Series slot that keeps track of whether the user has configure to use a distribution pattern (value = 1) or a constant pattern (value = 0).
– Algorithm To Use. Integer Indexed Series slot that keeps track of whether the user has configure to use Bisection (value = 1), Heuristic A (value = 2) or Heuristic B (value = 3).
2. Disable diversions. For the purposes of the yield study, diversion is controlled by directly setting the reservoir Diversion slot values, so you will need to disable the Diversion and Water Users objects that would divert water from reservoirs participating in the yield study. This can be done in the Run Analysis dialog by selecting the object’s row and then selecting Object, then Disable Dispatching. This should only be done for the specific reservoirs for which you are finding the yield. The other reservoir’s Diversion and Water User objects could remain enabled as desired.
3. Load the standard rulebased simulation ruleset that represents the policy in the basin. Use the Workspace, then Policy menu. Disable aspects of the policy (ruleset) that should not apply for the yield study. In particular, if you do not want any of the reservoirs in the subbasin to divert water, disable the Compute Reservoir Diversions rule. If you want all non-yield reservoirs to divert as defined, then you will need to modify the standard ruleset. First, create an identical subbasin to the one specified in the Compute Reservoir Diversions rule. Then remove the reservoir, diversion and water user objects for which you are finding the yield. Use this new subbasin in the Compute Reservoir Diversion rule. This way, you will compute reservoir diversions for all reservoirs except those for which you are finding the yield. Other rules may or may not need to be disabled depending on the desired policies in place during the yield study.
4. Import the yield study iterative MRM ruleset YieldStudy.rls.gz. For more information on Iterative MRM, see Iterative Runs in Solution Approaches.
a. Open the MRM policy set by selecting the workspace menu item Policy, then Iterative MRM Rules Set.
b. This will open the Iterative MRM Rules. To initiate the import into this set, select File, then Import Set. Select the file YieldStudy.rls.gz.
c. This will open the import dialog which will display the policy group and utility group contained in the file; confirm that the items being imported do not conflict with existing names in your MRM policy and continue with the import.
d. Set the Agenda Order of the MRM ruleset to “1,2,3,..”. This is done from the MRM Rules - Ruleset Editor View, then Show Advanced Properties menu. The Agenda Order is controlled by two toggles added to the bottom of the dialog.
e. Specify which algorithm you wish to use. Turn on only one of either Rule 1, 2, or 3. Rule 1 specifies a bisection algorithm to find the solution. Rule 2 employs a combination bisection/heuristic search algorithm (Heuristic A) which uses the bisection method when the yield is too high and a heuristic approach when the yield is too low. In this latter case, it estimates the additional yield necessary to lower the reservoir to the conservation pool during the critical period. Rule 3 triggers a faster heuristic algorithm (Heuristic B) which tries the intermediate yield first and then uses the calculation after each successful fun. See Algorithms for details on these algorithms.
f. Specify whether you want to use the average Yield or Distribute the Yield by enabling or disabling MRM rules 4 or 5. Rule 4 triggers a yearly distribution of yield. Rule 5 uses a constant yield.
g. The RPL set should now look similar to Figure 5.2 with your combination of enabled and disabled rules. No other rules in the set need to be disabled.
Figure 5.2 Yield study iterative MRM RPL set
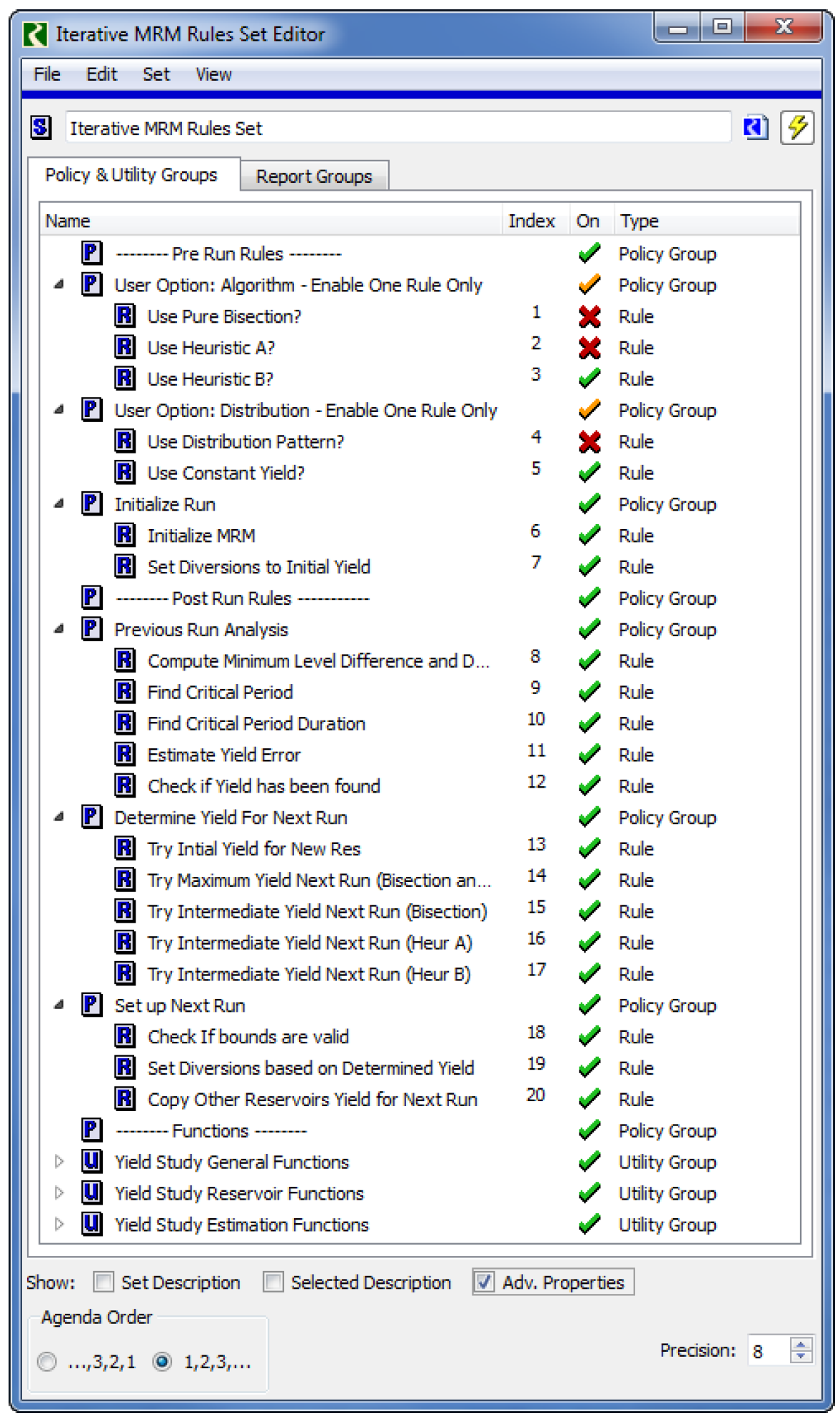
h. Figure 5.3 and Figure 5.4 show two additional changes you may need to make to the functions, depending on how the reservoirs are modeling inflows and evaporation.
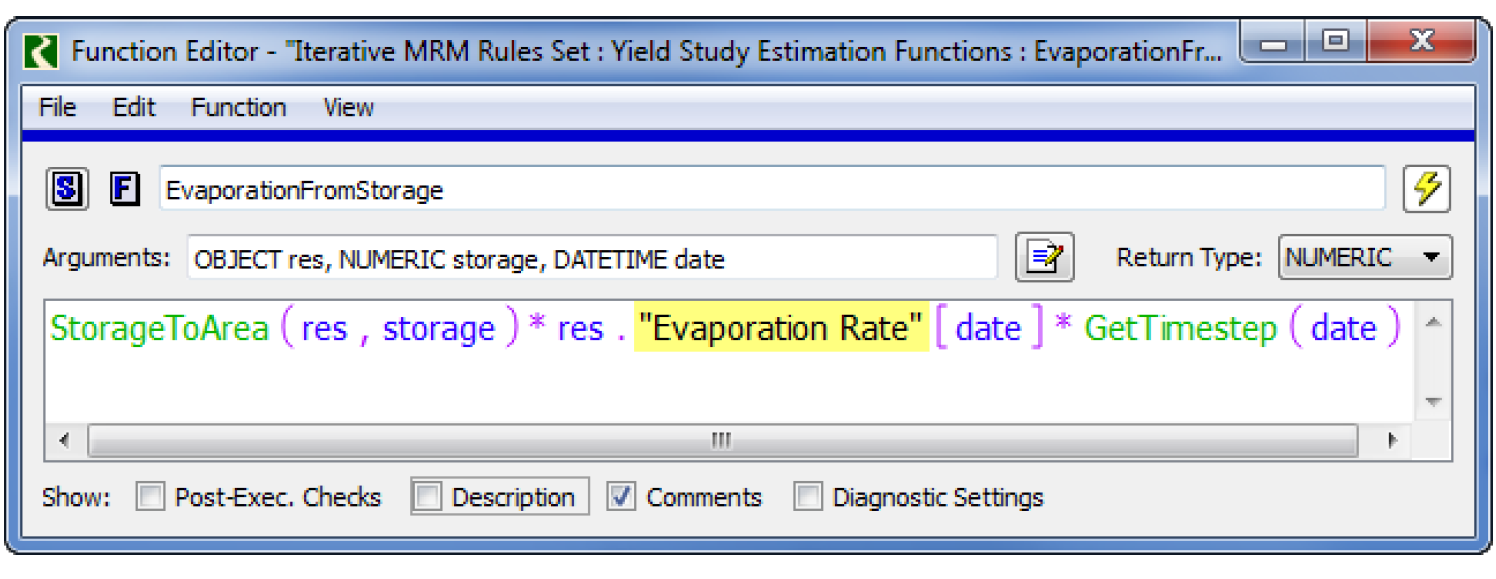
Note: If you are using Heuristic A or Heuristic B, you may need to change the function EvaporationFromStorage to access the correct Evaporation Rate slot. It should reference the slot with input data.
Figure 5.3
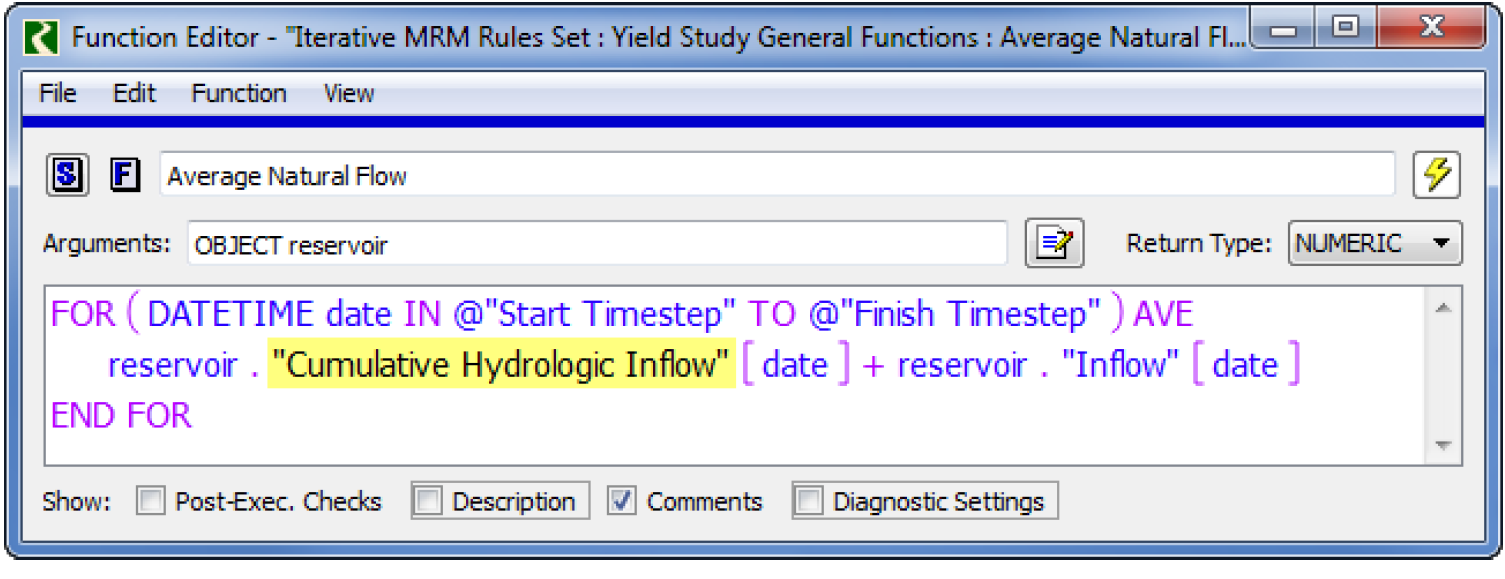
Note: If you are computing the maximum yield, you may need to change the function Average Natural Flow to access the correct hydrologic inflow slots. It should reference the slot with input data.
Figure 5.4
5. Create an MRM configuration for the yield study. See Iterative Runs in Solution Approaches for details on iterative MRM.
a. Open the Multiple Run Control Dialog by selecting the appropriate workspace menu button or selecting Control, then MRM Control Panel.
b. Create a new configuration MRM control dialog by selecting Configuration, then New.
c. To edit the new configuration, double-click its name in the MRM Run Control Dialog.
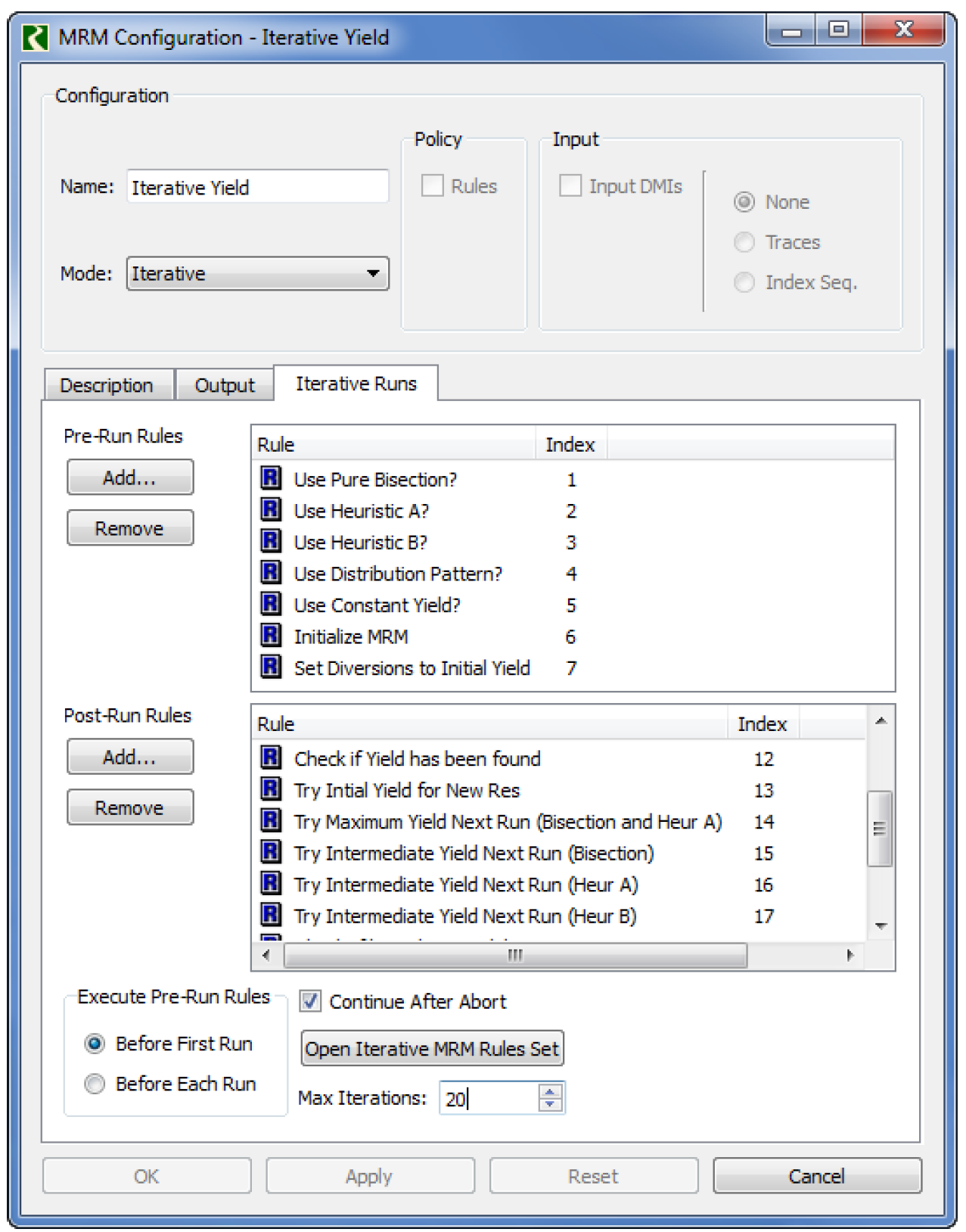
d. This will open the MRM Configuration Dialog. Select Iterative mode and then select the Iterative Runs tab.
e. In this tab, use the Add button to add the first seven (1–7) rules to the upper Pre-Run Rules box.
f. Use the second Add button to add the remaining rules, 8–20, to the Post-Run Rules box.
g. Select Continue After Abort and set Max Iterations to a number which is appropriate.
h. Select that the Pre-Run Rules should execute Before First Run. Your screen should look similar to Figure 5.5.
i. Select OK to apply the changes and close the window.
Figure 5.5 Iterative MRM configuration
6. At any time before, during or after the run, you can open an SCT to see all the results of the run to that point. The SCT file is in YieldStudy.sct. If doing a multiple reservoir yield study, insert additional columns to show each column of the Yield Agg series slot. The column labels of the SCT can be renamed using the Slots, then Set Label/Function menu. Make sure the SCT is unlocked or this option will not be available.
7. Conduct the MRM run as follows: In the Multiple Run Control, select the new MRM configuration on the Multiple Run Control dialog and select the Run button.
8. After the run, the sequence of values tried for the individual reservoir yields may be found in the Yield slot of the Yield Study Data object. The easiest way to view all results is through the YieldStudy.sct.
Revised: 12/06/2024