
Multiple Run Management
The following changes were made to Multiple Run Management.
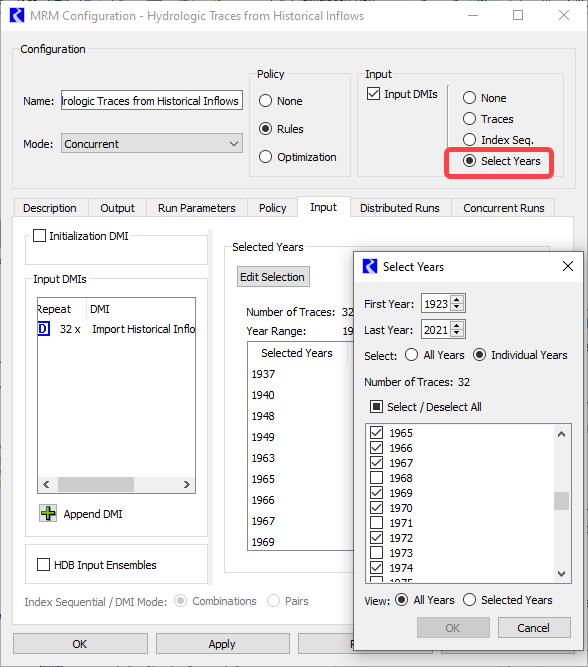
Configure Traces by Selecting Years
A new approach for specifying inputs to a multiple run was introduced. In addition to Index Sequential and Traces, now you can choose to Select Years. This allows you to define the MRM traces based on selected historical years. The historical years in the source data are mapped to the run range. The number of traces simulated corresponds to the number of years selected. When the Run Range is longer than one year, the selected year indicates the start year of the input for that trace, and the data extend as far as necessary in the historical data to map to the entire run range. The trace numbers reported in the output will correspond to the years selected. For more details see Select Years in Solution Approaches.
Figure 4.5 Screenshot of MRM configuration with new Select Years feature
Distributed MRM
The following changes were made to Distributed MRM.
Combine RDF in parallel
In distributed MRM each individual MRM writes a partial RDF file containing the traces it simulated. At the end of the overall run, the partial RDF files are combined to create a single RDF file, and optionally the RDF file is used to generate an Excel workbook. Previously, this post processing was done serially.
Distributed MRM now performs the post-processing in parallel, taking advantage of multiple cores to reduce the time to perform the post-processing.
Distributed MRM from a script action
A distributed multiple run can now be initiated from a script action. See Execute MRM Run for more information. See Execute MRM Run in Automation Tools for documentation on this action.
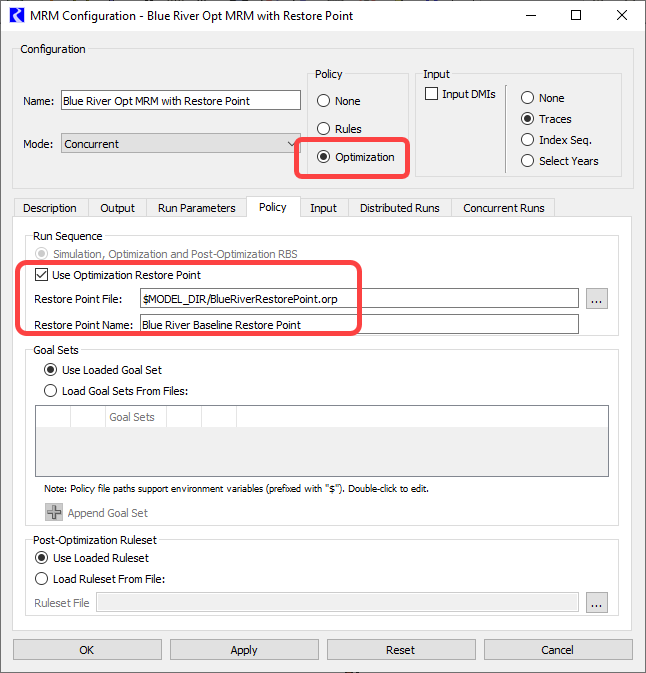
Optimization Runs in MRM
MRM was enhanced to support optimization runs, including the standard optimization sequence of Simulation, Optimization, Post-optimization Rulebased Simulation and optimization that uses a Restore Point for an advanced start (see Optimization Restore Points for Advanced Start). In the MRM configuration, specify Optimization as the policy option, and then optionally specify whether a restore point is being used, the restore point name and the restore point file (for distributed MRM). The optimization goal set and post-optimization ruleset can either be saved in the model or loaded from a separate file. See Optimization in Solution Approaches for more information on optimization in MRM.
Figure 4.6 Screenshot of MRM configuration with new Optimization Policy specification
Iterative MRM in RiverSMART
A RiverWare Iterative MRM run can now be part of a RiverSMART study. Technically, Distributed MRM now allows iterative mode. It is not possible to distribute individual runs in an iterative MRM, as they must be performed in order. But now an iterative MRM can be part of a RiverSMART study.
Trace Number in Diagnostic Output messages
In MRM, the trace number was added to run started / finished diagnostics, for example:
------ Rulebased Simulation RUN STARTED (MRM run 2 of 3, trace 14) ------
------ Rulebased Simulation RUN FINISHED (MRM run 2 of 3, trace 14) ------
This can be particularly helpful when the trace number does not match the run number, such as for distributed MRM log files or when using the Select Years input mode.
Ensemble Data Tool
The Ensemble Data Tool (EDT) is used to visualize and analyze the RDF results of an MRM run within RiverWare. In this tool, import an RDF file created from an MRM run to create an Ensemble Data Set object. Then, plot traces and perform statistical analysis on the trace data. For more information on the EDT, see Ensemble Data Tool in Solution Approaches.
Ensemble Data Set Object
Ensemble data sets are now stored on slots on a new object type, the Ensemble Data Set object, with two variations of the icon. In Figure 4.7, the top icon shows an Ensemble Data Set containing RDF trace outputs. The lower icon shows an Ensemble Data Set object containing analysis results.
Figure 4.7 Screenshot of new Ensemble Data Set objects on the workspace
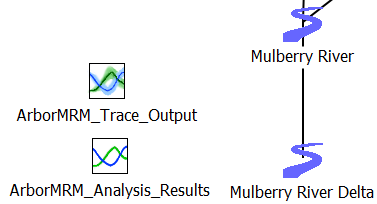
The data is a collection of slots within a new Ensemble Data Set object. By showing and saving the data on an object, it allows the full range of RiverWare functionality for slot data to be applied to ensemble data, for example tabular display, plotting, and output.
Figure 4.8 Screenshot of an Ensemble Data Set object showing one slot per trace
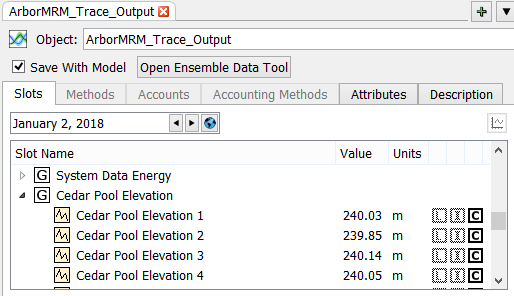
For more information on Ensemble Data Sets, see About Ensemble Data Sets in Solution Approaches.
Analysis in the Ensemble Data Tool
The Ensemble Data Tool now provides direct support for ensemble data set analysis that was previously only available within scripts. Now you can perform the analysis interactively from the EDT or from scripts, allowing them both to perform the same sorts of analysis.
Figure 4.9 Screenshot of the Ensemble Data Tool and Analysis dialog

New Analysis Types
Two new types of analysis were added to the Ensemble Data Tool. These analysis types are available interactively from the Ensemble Data Tool or from script actions:
• Duration curve (see also Compute Duration Curve for information on the analogous script action)
• Regression on scalar data, across traces (see also Compute Regression for information on the analogous script action)
Extended RDF Output
Support was added for MRM to generate RDF output before the run start date or after the run end date. Now, in the output control file, specify the start_timestep and end_timestep for each slot. For example
– start_timestep=“24:00 November Max DayOfMonth, 1996”
– end_timestep=“Start Month Start DayOfMonth, Start Year - 2 days”
For more information, see Start and End Timestep Specification in Solution Approaches.
Use Accounting Controller in MRM Run Parameters
When Accounting is enabled, a new Use Accounting Controller toggle is shown in the MRM configuration for Concurrent mode. This toggle allows you to decide if the multiple runs should use the accounting version of the controller or the non-accounting version. By default, the box is checked to replicate previous behavior. De-select the option if you have accounting enabled but do not want to use an accounting controller for the multiple runs.
For more information, see Use Accounting Controller in Solution Approaches.
Revised: 07/03/2024